

Table of Contents
•
Model-based RL
◦
How it can be used for multi-task & meta-learning
•
Model-based RL with image observations
◦
or other high-dimensional inputs
•
Model-based meta-RL

Model-based RL
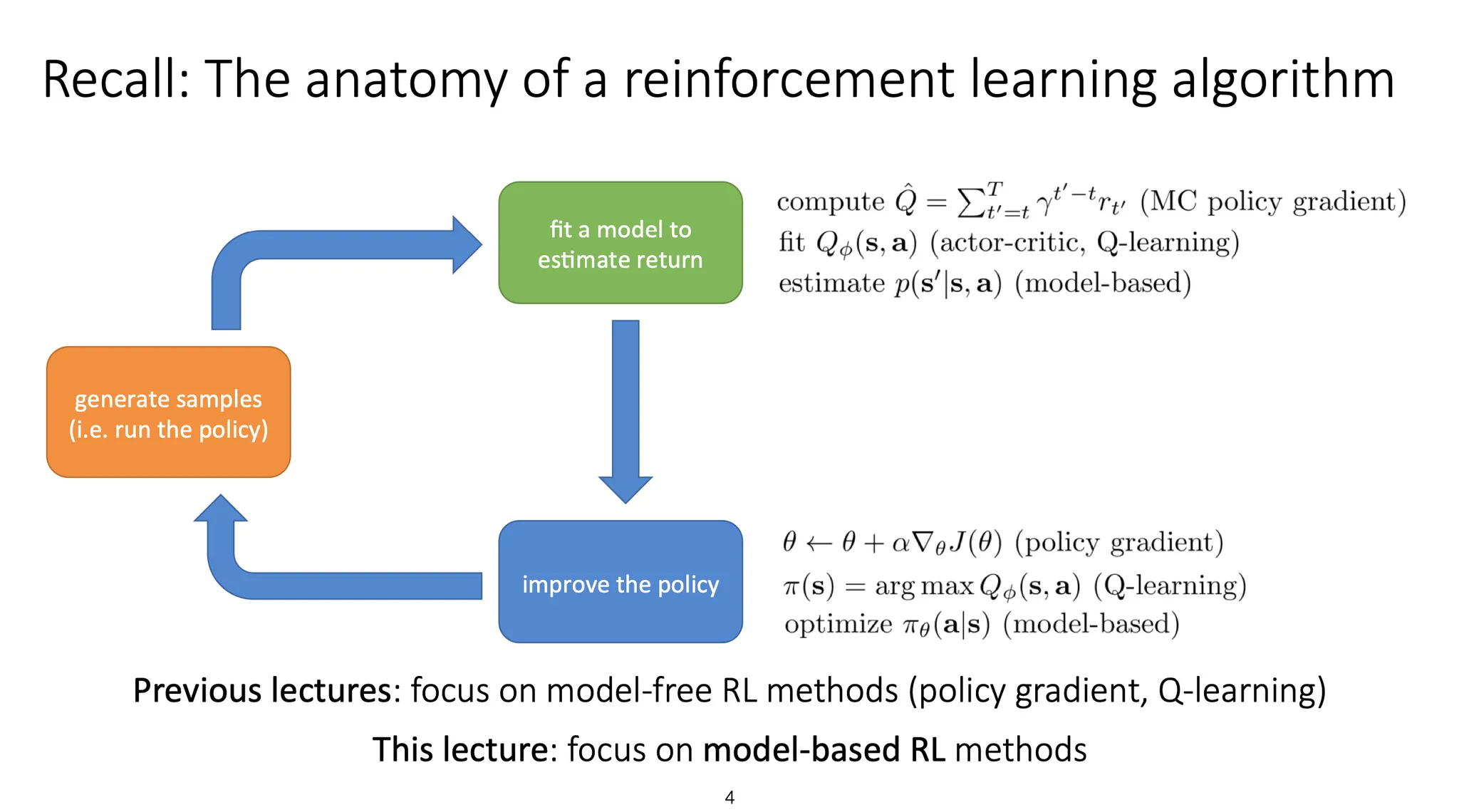
RL algorithm에 대해 복습해보면, 어떤 policy에 따라 sample들을 만들어내고, 그 sample에 따른 reward를 계산하여 model을 fit 한다. 이때 크게 3가지 방법으로 구분할 수 있는데, policy gradient, Q-learning, 그리고 model-based가 있다. 이렇게 fit 된 model을 바탕으로 policy를 update한다.
이전 강의(Lecture 6)에서는 policy gradient와 Q-learning 기반의 방법들을 다뤘고, 이번 강의에서는 model-based RL을 다룬다.
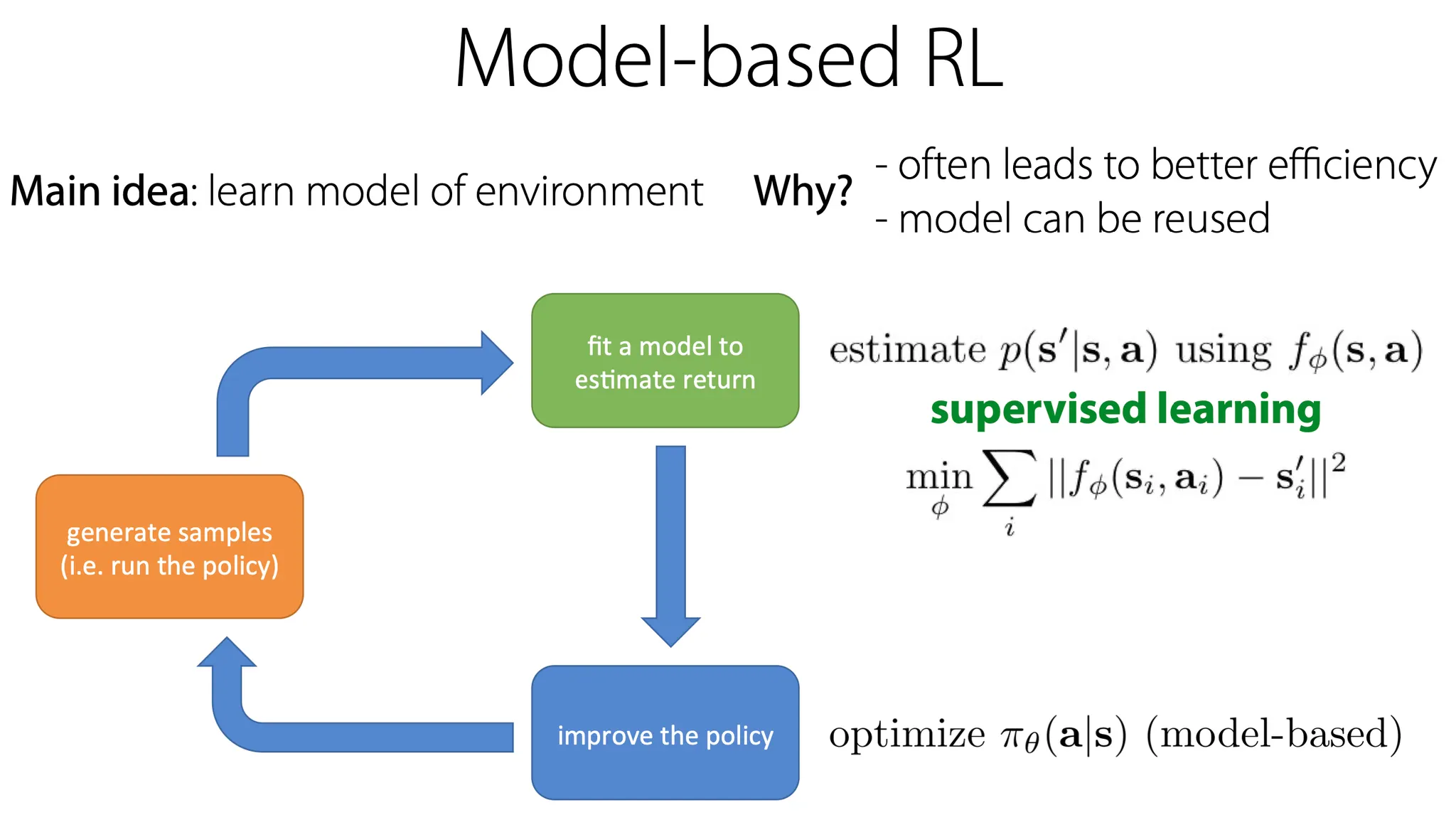
Model-based RL은 기본적으로 environment에 대한 model을 학습하는 것이다. 이 방법의 장점은 대부분의 경우에 sample efficient 하고, model이 서로 다른 task와 objective에 대해서도 재사용될 수 있다는 점이다.
Model-based RL은 dynamics에 대한 model을 estimate 하기 위함이고, 이는 결국 environment에서 현재 state()와 action() 선택지를 이용해 다음 state()를 예측하는 일종의 supervised learning problem이 된다.
이 때, dynamics라는 것은 를 의미한다.
State는 discrete하거나 continuous 할 수도 있고, model이 deterministic하거나 stochastic할 수도 있다.

그런데 왜 model-based RL이 multi-task RL과 meta-RL에 중요할까?

이에 대답을 하기 위해서는 RL task가 무엇인지 다시 복습해볼 필요가 있다.
RL에서의 task는 위와 같이 정의된다. State space, action space, initial state distribution, dynamics, reward가 모두 정의되는 MDP 상황이다.
그런데 생각보다 dynamics(가 크게 다르지 않은 경우가 많다. 예를 들어 중력은 모든 물리 환경에서 동일하게 적용된다거나, 어떤 물체를 어디로 옮기든간에 물체를 집는 방식은 크게 다르지 않다. 이렇게 대부분 reward function 만 다른 경우가 많다.
이런 경우에는 적절한 model 하나만 찾는 single-task problem으로 생각할 수 있고, multi-task model-free 방법들보다 쉬운 상황이다. 즉, 좋은 model 하나를 학습해서 서로 다른 task에 적용시켜 각각에 맞는 policy를 optimize 하도록 하면 된다.
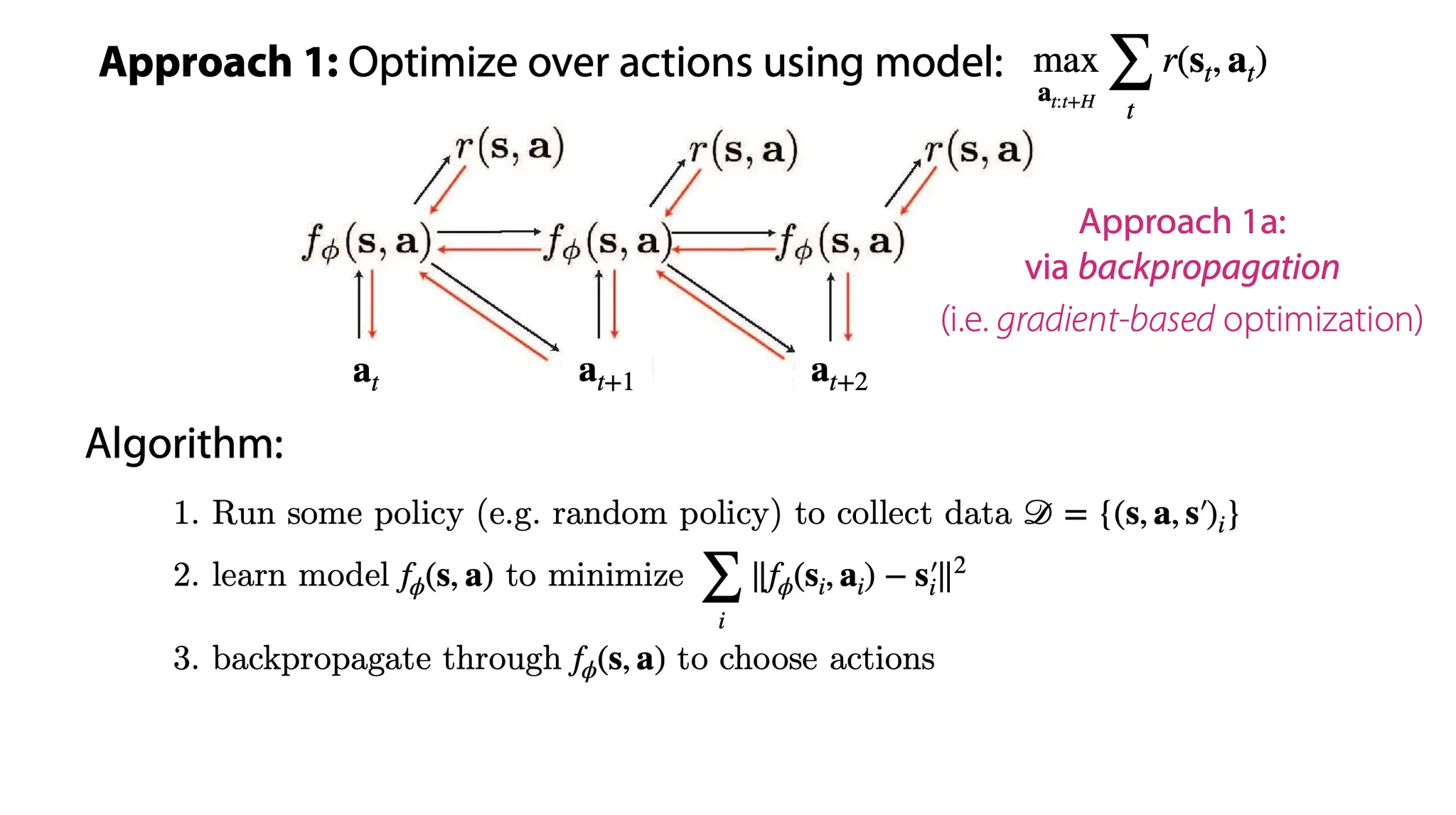
Model-based RL을 하기 위한 방법 중 하나로, action에 대해 model을 optimize할 수 있다.
그 중에서도 Gradient에 기반하여 backpropagation을 하는 방법은
1.
어떤 policy에 기반해 data(current state, action, next state) 를 수집하고
2.
model 를 MSE를 최소화하도록 학습한다.
3.
그 후, error를 action에 대해 backpropagate한다.
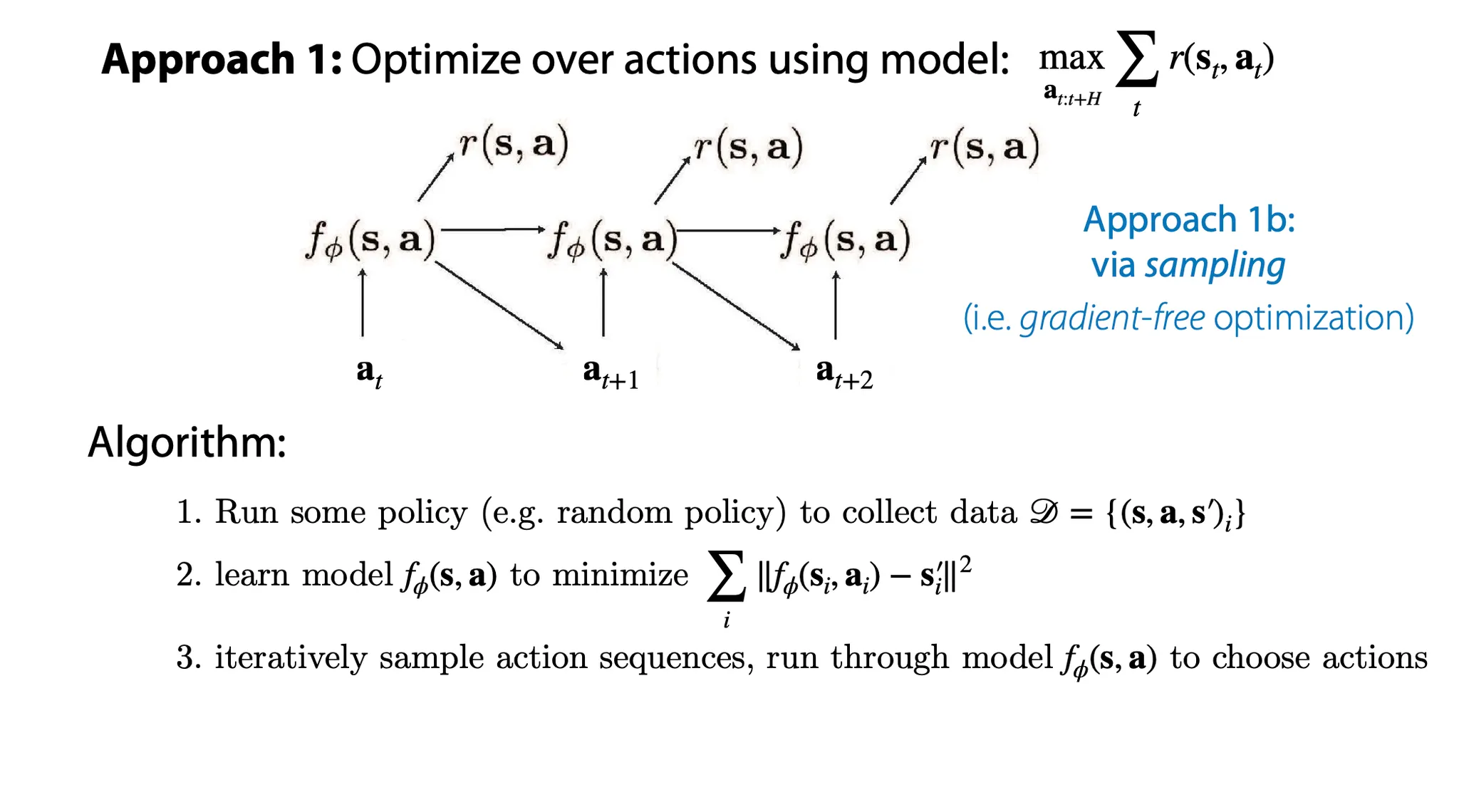
Action에 대해 model을 optimize하는 다른 방법으로, sampling을 이용할 수 있다.
1.
어떤 policy에 대해 data를 수집하고
2.
model을 MSE를 최소화하도록 학습한다.
3.
반복적으로 action sequence를 sampling 하여, model을 가장 적은 MSE가 나오도록 학습한다.

이 sampling 기반 optimization의 단점은 무엇일까?
먼저, optimization 기반이기 때문에 별로 좋지 않은 학습을 했음에도 불구하고 그것을 exploit해서 overly optimistic할 수 있다.
또, sampling 기반이기 때문에 거의 optimal하게 학습을 했음에도 그 다음 iteration에 optimal에서 완전히 멀리 떨어진 sample을 보게 되면 말짱 도루묵이 될 수도 있다.
이는 학습된 model로 새로운 data를 만들고, 그 data로 model을 다시 fit 하는 것으로 일부 해결할 수 있다.
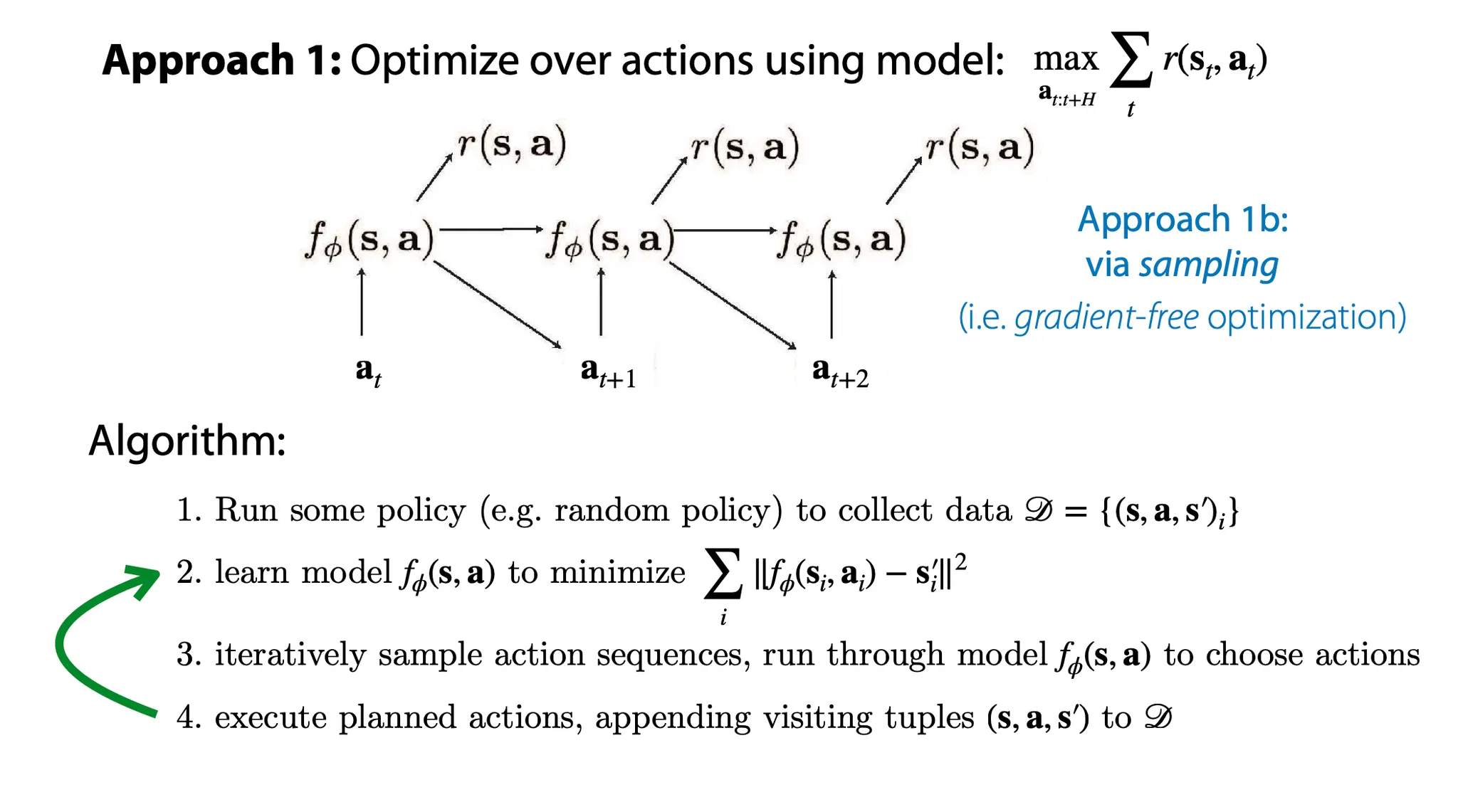
즉, 이전의 algorithm에서 model 학습 이후에 그 model로 다시 action을 수행해보고, 그렇게 생성된 data를 다시 사용해서 model을 한 번 더 학습한다.

하지만 여전히 좋은 global model을 학습하기에는 한계가 있다.
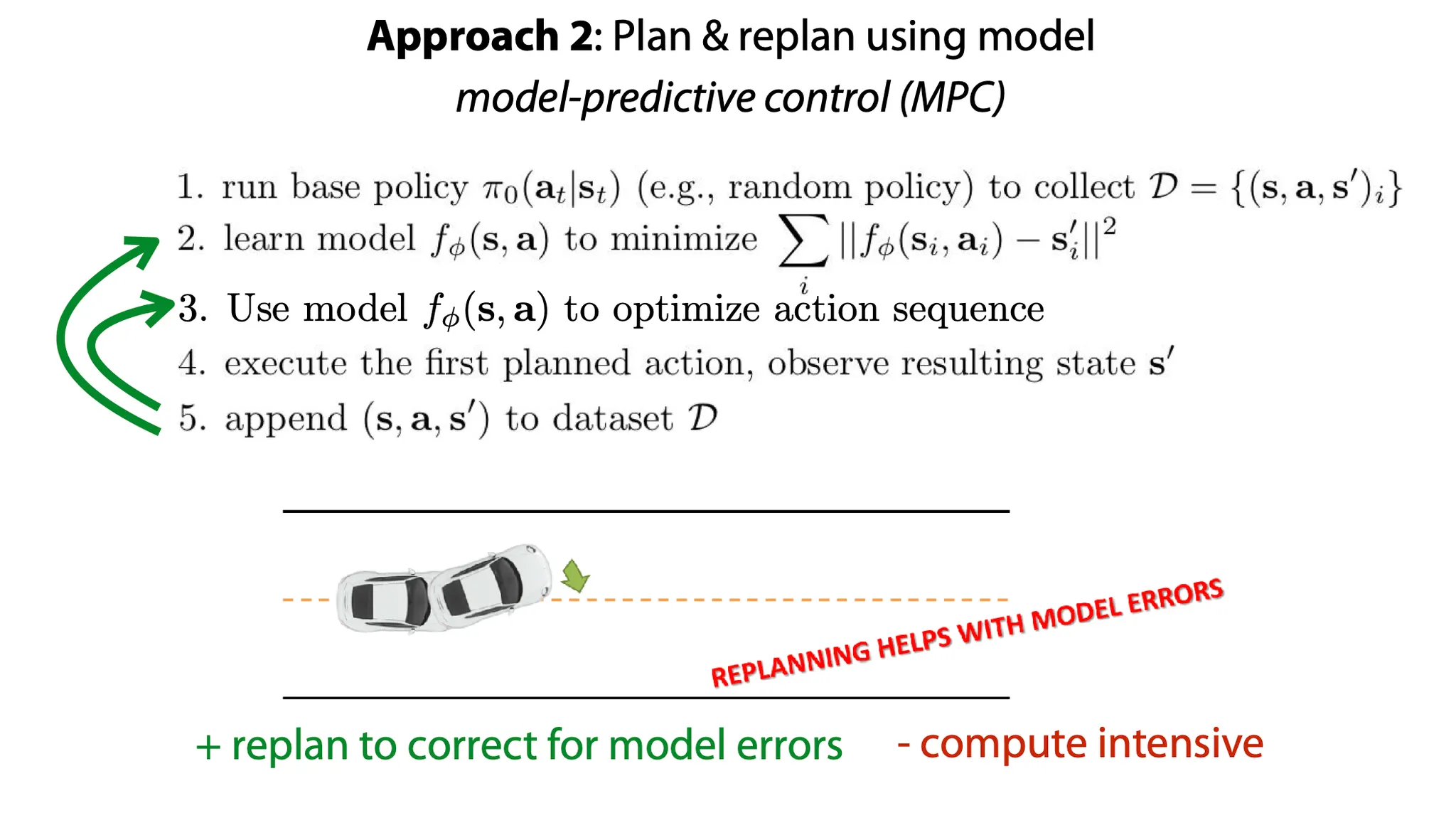
두 번째 방법으로는 model-predictive control(MPC)라고 부르는 방법으로, model이 잘못 학습되기 전에 보정을 해줄 수 있는 방법이다.
1.
어떤 policy에 의해 data (current state, action, next state)를 수집하고
2.
model을 그 data에 fit 한다.
3.
학습된 model로 action sequence를 optimize 하고?
4.
기존에 계획되었던 action을 수행하고, next state를 관측해 새 data를 만든다.
5.
그 data를 다시 model에 적용해서 action sequence를 수정한다.(이 단계가 model이 잘못 학습되기 전에 action을 보정해주는 단계이고, 이 과정에서는 model은 학습 되지 않는다.)
6.
4, 5를 다시 수행한 뒤 나온 data를 dataset에 포함시킨다.
이 방법의 장점은 model의 error를 줄이기 위한 replanning을 할 수 있다는 점이다. 하지만 계산량이 많다.
Gradient 방식의 경우, 계산량을 줄이기 위한 방법 중 하나로 “sequence of action”이 아니라 “policy”에 대해 error를 backpropagate 할 수 있다. Sampling 방식의 경우는 비슷하게 특정 sequence of action에 대해 optimize했다면, 그 action들을 생성하도록 policy를 학습시킬 수 있다.
Task에 따라 dynamics를 학습하는 것과 policy를 학습하는 것 둘 중에 서로 적합한 경우가 다를 수 있다. 예를 들어, 물을 따라야 하는 task에 대해서는 물이 흐르는 dynamics를 학습하는 것보다 그냥 로봇팔로 물이 들어있는 물체를 기울이는 동작(policy)이 더 학습하기 쉬울 것이다. 이 경우는 model-free appraoch가 더 쉬울 수 있다. 반면에 특정 position으로 물체를 밀어넣으려고 한다면, 물체를 밀어넣는 dynamics는 꽤 간단해서 한 번 model을 이용해 dynamics를 학습해 놓으면 여러 task에 대해서 적용할 수 있을 것이다.
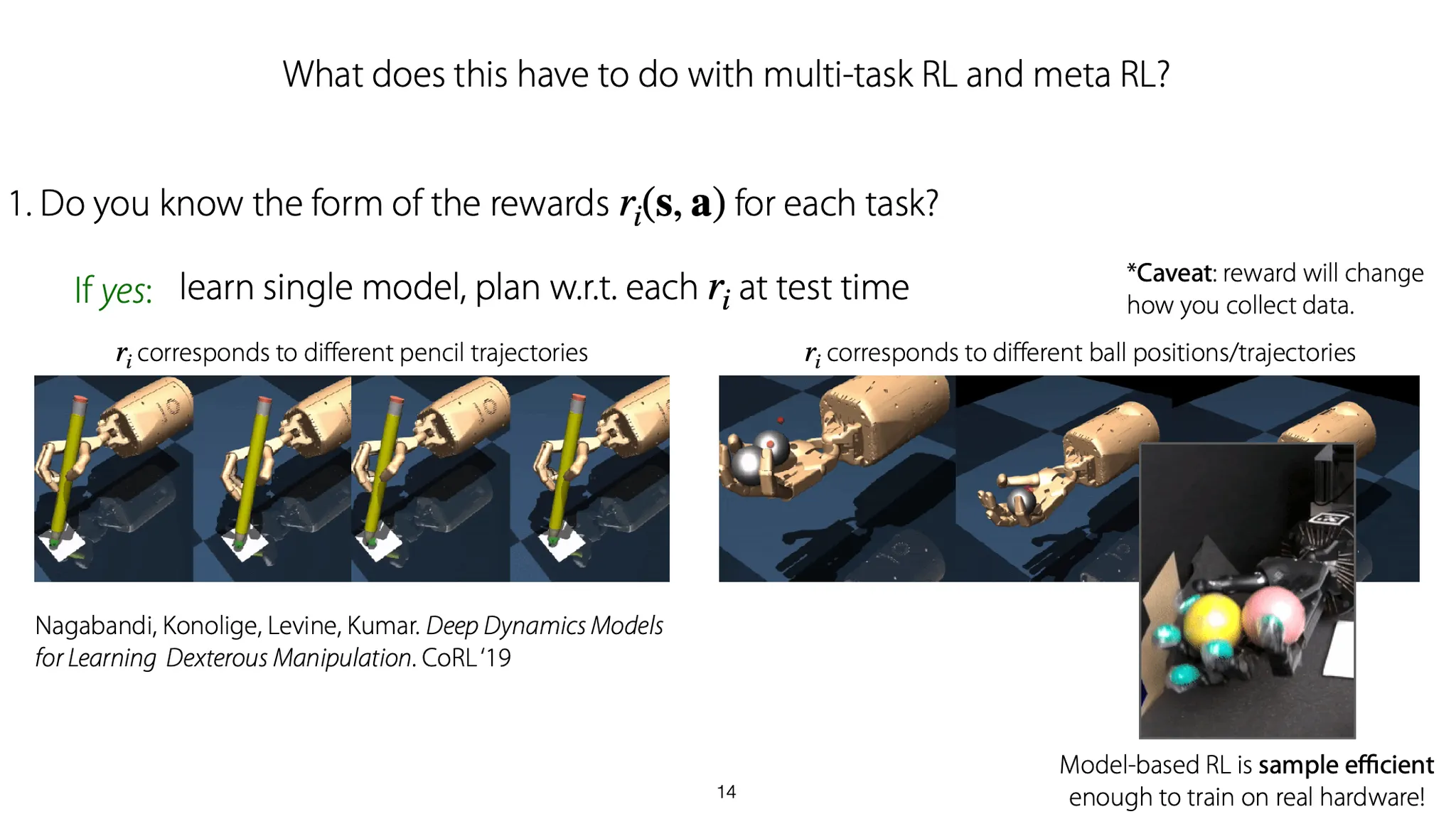
각 task에 대해 reward의 형태를 잘 정의할 수 있다면, 하나의 model을 학습해서 test time에 각 reward에 맞게 plan을 짜면 된다.
예를 들어, 로봇팔로 숫자를 쓰는 task에 대해서는 팔을 움직이는 dynamics를 model로 학습하고, 각 task에 따라 숫자를 써내려나가는 trajectory에 대해 reward를 부여해 다른 state distribution을 학습시킬 수 있다.
또 다른 예로 손 안에서 공을 굴리는 motion에 대해, 손을 움직이는 dynamics를 model로 학습하고, 서로 다른 task에서는 서로 다른 state distribution에 대해 학습할 수 있다.

Reward를 잘 모르는 경우에는 어떻게 할까? 각 task에 맞게 reward를 학습하고, 그 reward를 maximize하도록 학습할 수 있다. 예를 들어, 몇 개의 positive example을 주고, binary reward function을 학습한다. 그리고 그렇게 학습한 reward를 maximize 하도록 model을 학습한다.
Model-based RL with image observations
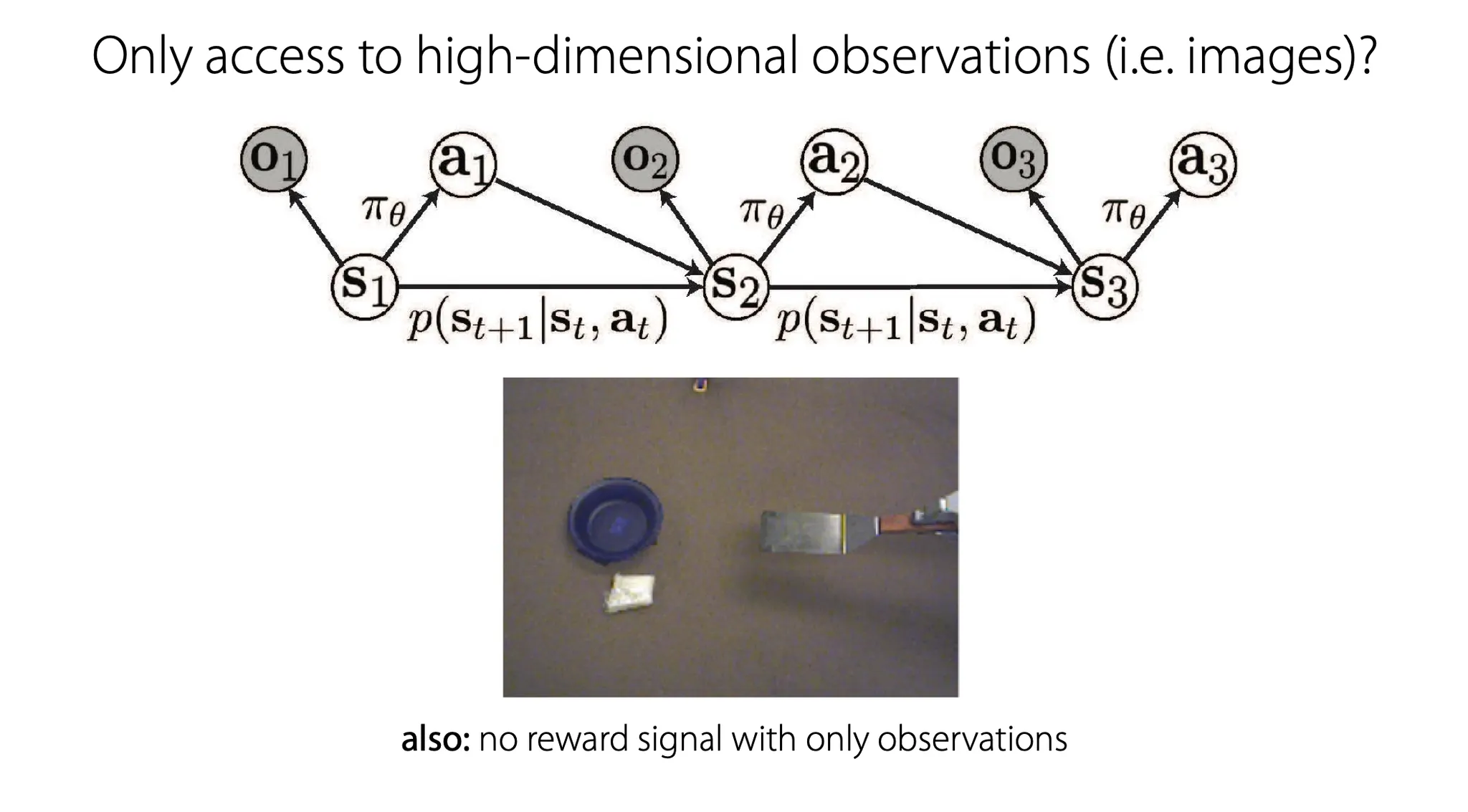
Image observation이 있을 때, model-based RL을 수행하는 것을 좀 더 자세히 살펴보자.
여기서는 보통 image 만 주어지고, reward function은 주어지지 않는 상황이다.

Image라는 일종의 high-dimensional observation 만 주어졌을 때, 어떻게 model을 학습시킬 수 있을까? 크게 두 가지 option이 있다. 하나는 image classifer를 학습하는 것이고, 다른 하나는 goal image를 제공하는 것이다.
세 가지 접근 방법을 소개한다.
1.
Latent space에서 model을 학습
2.
직접 observation(video 등)에 대해 model을 학습
3.
Raw observation이 아닌 alternative quantity 예측

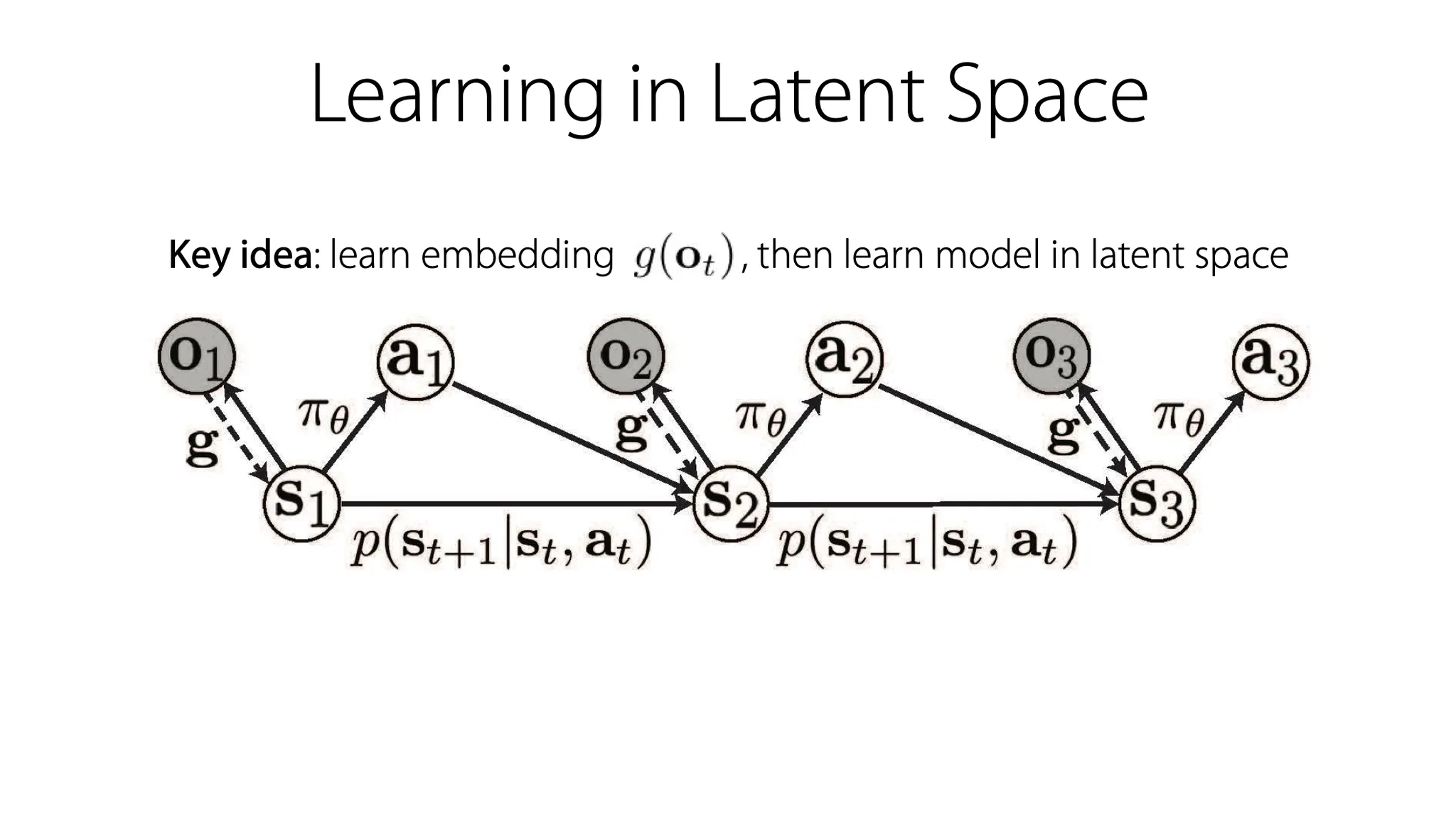
Latent space에서 model을 학습하는 방법.
Image라는 data는 high-dimension 이므로, embedding function 를 학습하고, 그 latent space에서 model을 학습하는 방법이다.


Algorithm으로 살펴보면,
1.
어떤 policy에 따라 action을 수행하고 data를 수집한다.
2.
observation을 embedding function 에 통과시켜 state 를 만들고, model을 의 형태로 디자인한다.
3.
Action sequence를 optimize하는데 model을 사용한다.
4.
계획된 action들을 수행하고, 새로 만들어진 data를 기존 data에 넣는다.
이 때 action을 optimize하기 위한 reward는 어떻게 정의할까?
Goal observation이 있다면, 일종의 negative distance로 정의할 수 있다. 그리고 만약 어떤 action에 대한 penalty가 있다고 하면(예를 들어, 움직일 때마다 에너지 소모, 부품 소모가 있다면) 그것도 반영할 수 있다.
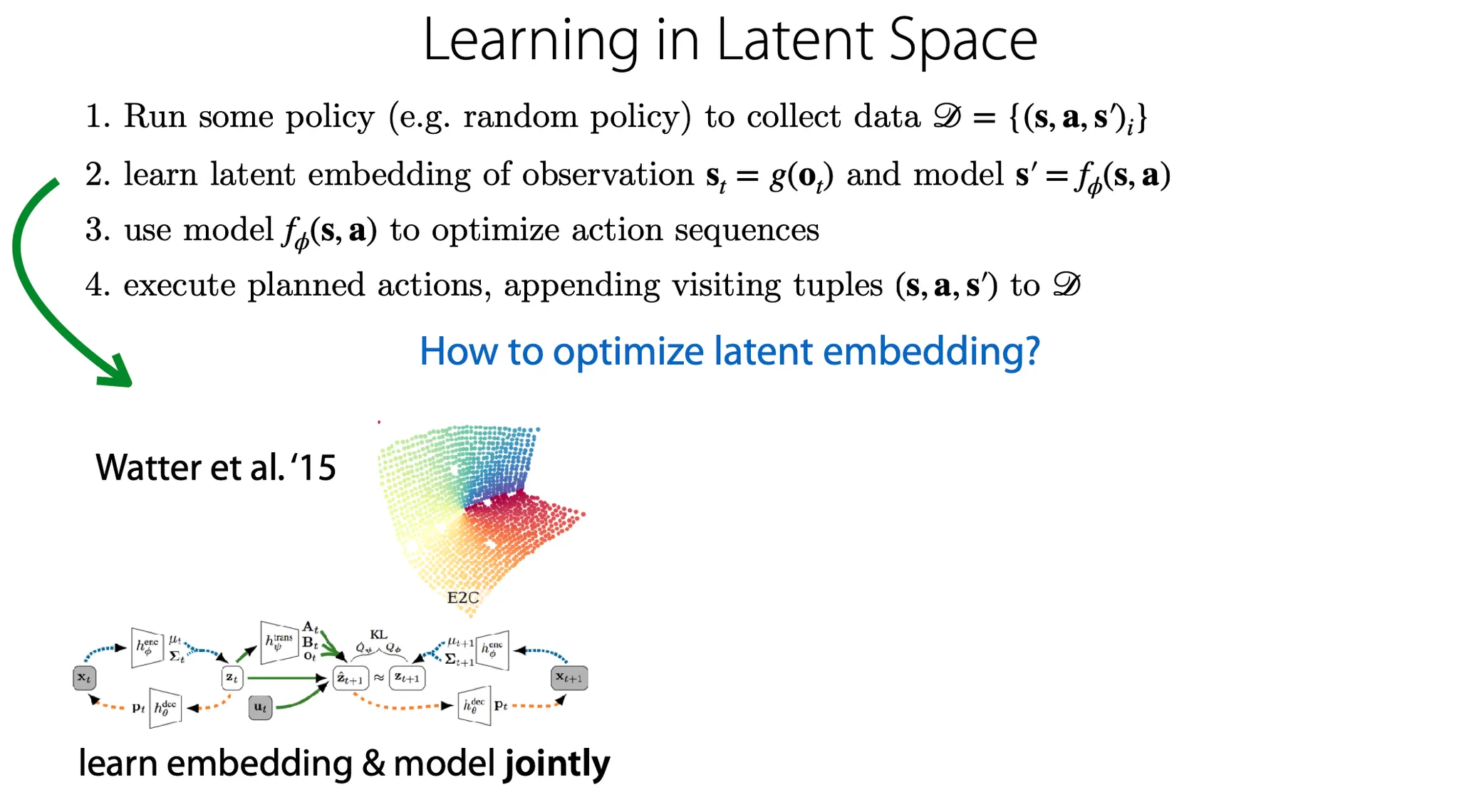
그럼 Latent embedding은 어떻게 optimize할까? ——————- 여기서부터 다시 듣기
하나의 방법으로는 transition의 graphical model을 만들 때, state의 pair에 대해 VAE를 적용하는 방법이 있다. 이 방법은 embedding과 model을 jointly 학습한다.
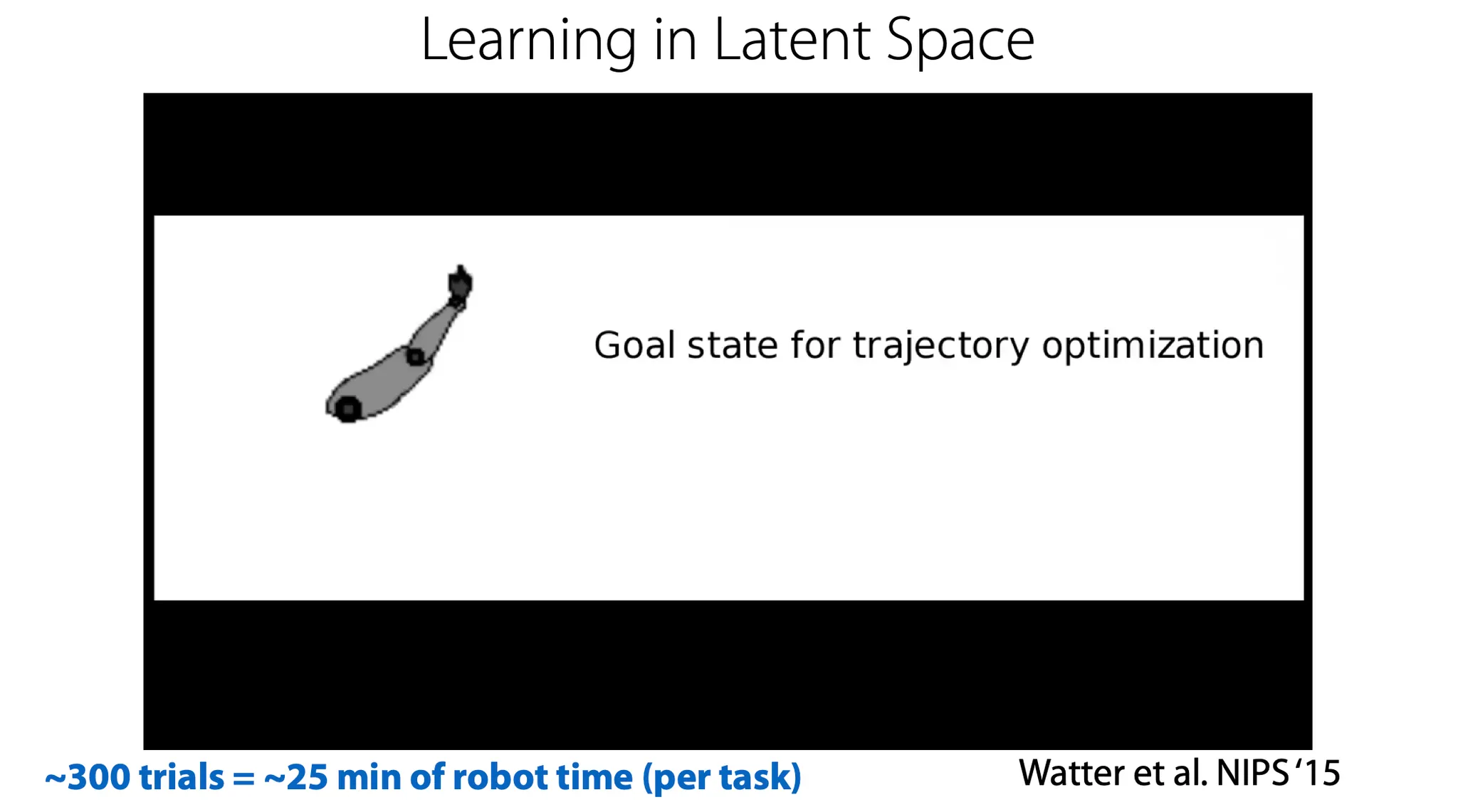
이 방법은 efficient 해서 굉장히 빨리 학습이 진행된다.
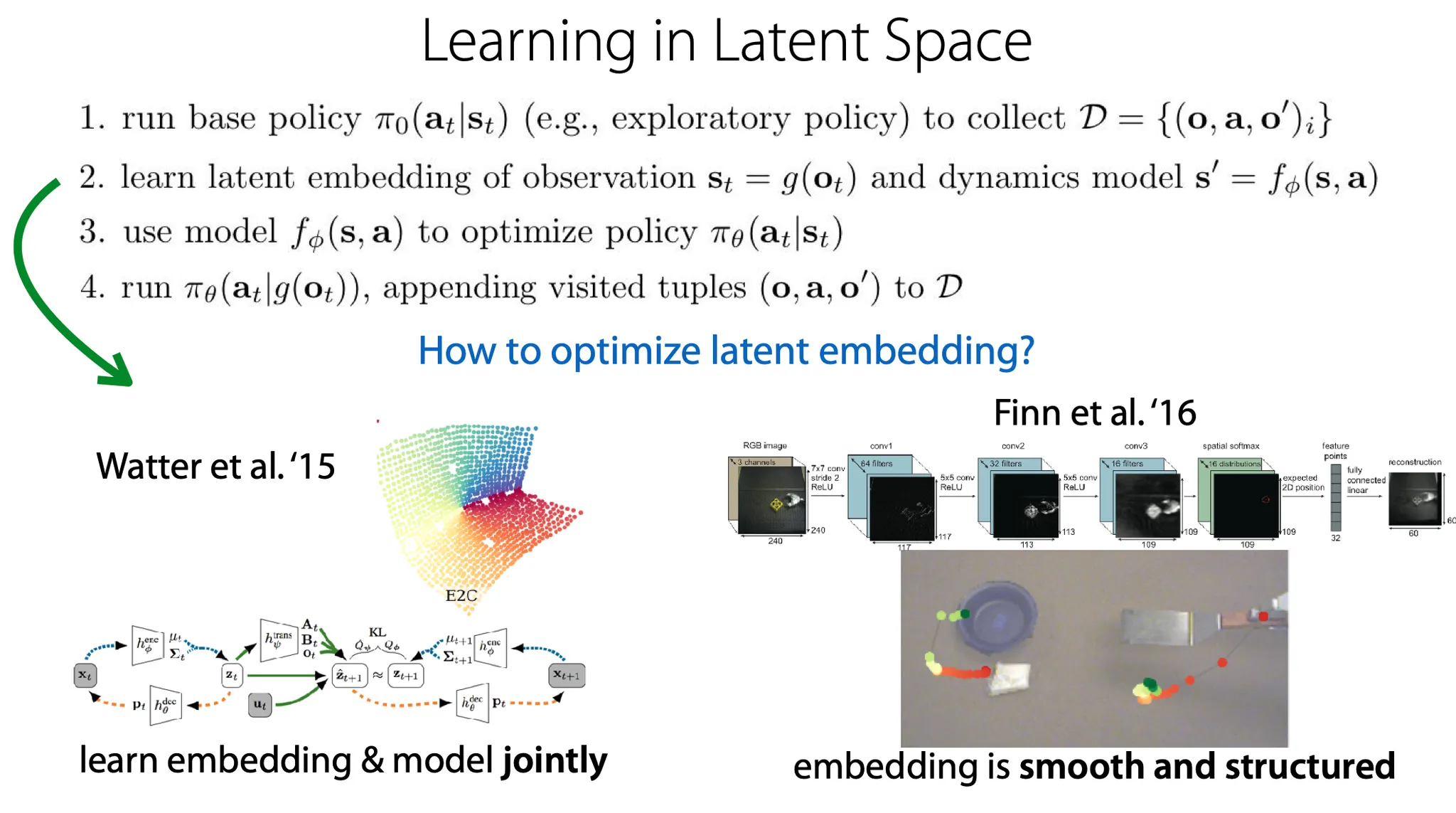
다른 방법으로는 latent space 상에서 image의 key point(latent representation)에 대응하는 방법이 있다.. ← 뭔 말인지 모르겠음
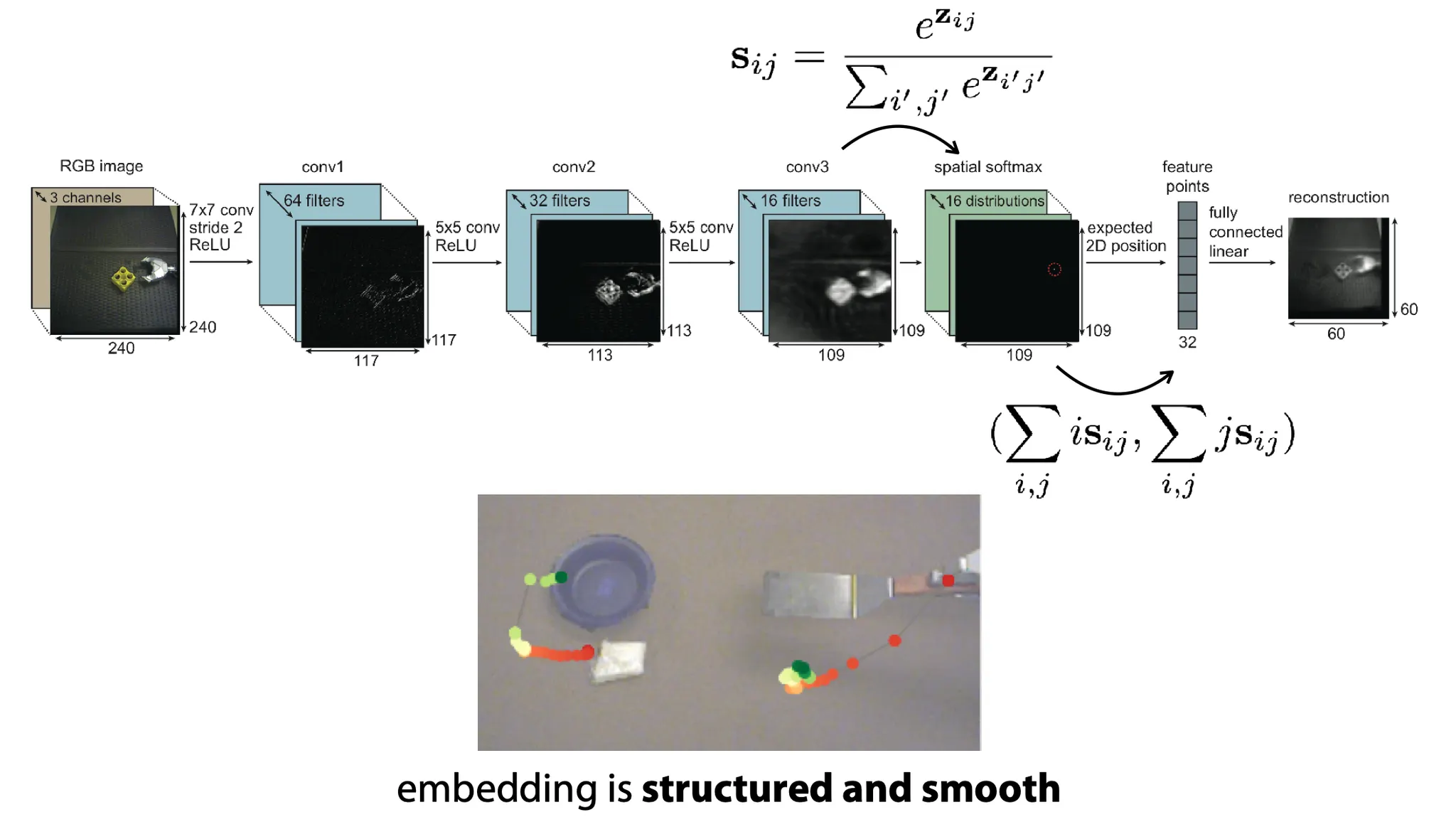





왜 그냥 embedding과 model을 model error에 대해서 학습하지 않고 image를 reconstruct 해야할까?


참고로, model-free approach에서도 low-dimensional embedding이 유용한 경우가 있다.

Latent space 말고, image space에서 직접 modeling 하는 방법에 대해 살펴보자.

latent embedding이 없는 형태.

1.
어떤 policy에 의해 data를 수집한다. 따로 embedding function 없이 그냥 raw observation을 사용한다.
2.
MSE를 최소화 하도록 model 를 학습한다.
3.
model을 사용해 action sequence를 optimize한다.
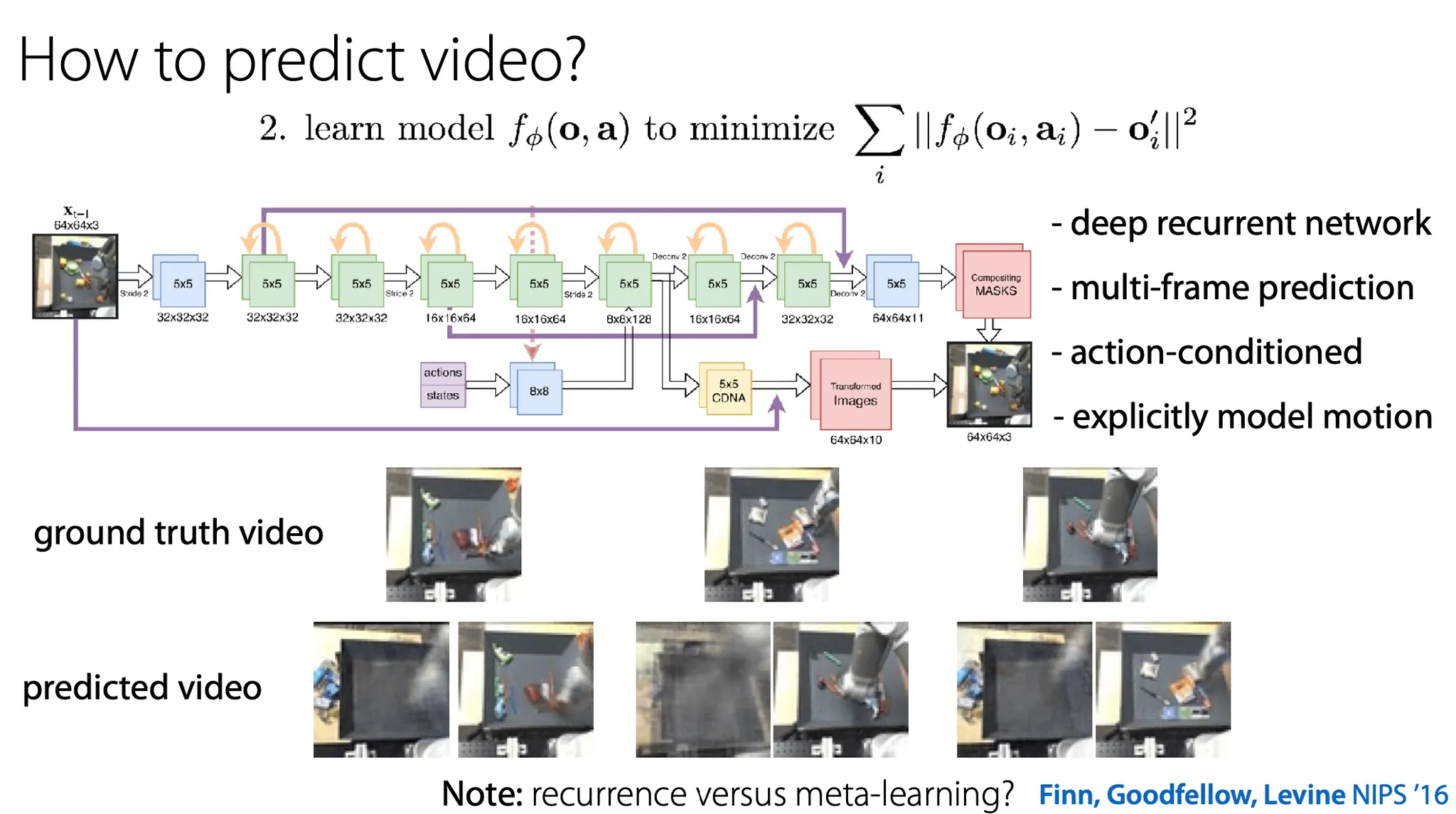
Video를 어떻게 예측할까?
2016년에 제안된 방법으로는 deep recurrent network를 사용해 여러 frame을 예측하는 task를 수행할 때 action(및 그 state에 대한 다른 정보도 사용 가능. e.g. 로봇 팔의 위치 등)에 condition 되어 있고 motion(pixel)을 explicit하게 modeling 하는 방법이 있다.
하지만 model이 pixel을 직접 generation 하지는 않고(computation load가 너무 높을 것이기 때문), 어떤 previous image에 대해서 그 image의 transformation이 어떻게 될지를 예측한다.
Ground truth와 비교하면 predicted는 다소 blurry 하다.

Model을 사용해서 action sequence를 optimize하는 planning은 sampling에 기반하여 다음과 같이 진행한다.
1.
초기 image에 대해 potential action sequence를 여러 개 sampling 해본다.
2.
그리고 각 action sequence에 대해 예측을 해본다.
3.
가장 좋은 것을 고르고, 그 action을 실제로 수행한다.
4.
1 ~ 3번을 반복한다.

먼저 Goal을 정한다.

하나의 model로 여러 비슷한 task를 수행하도록 할 수 있다.
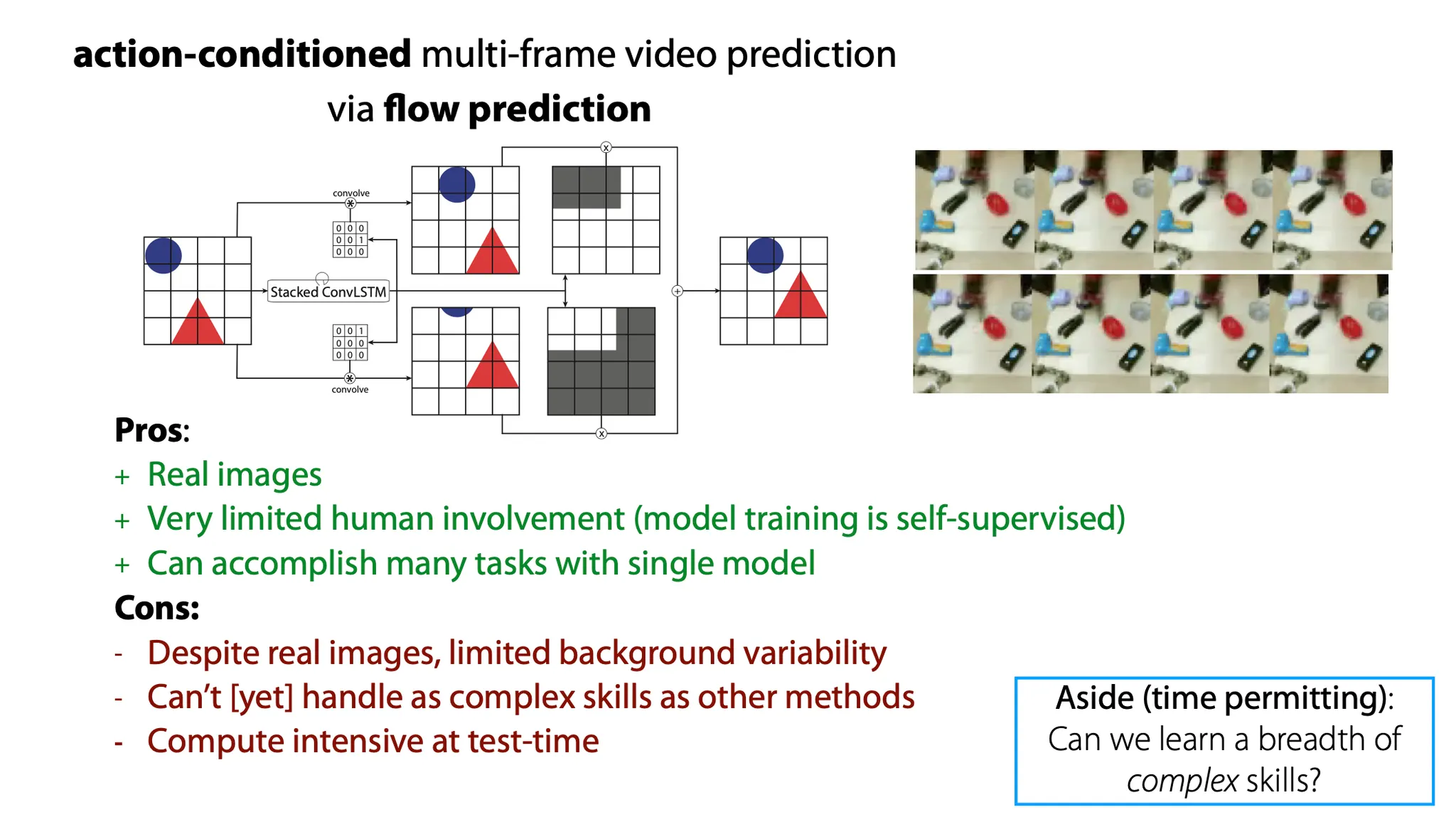
Flow prediction 방법의 장단점을 정리해보자.
장점
•
Dimension reduction 없이 real image를 사용한다.
•
인간의 개입이 거의 없이 self-supervised 방식으로 training 된다.
•
하나의 model로 여러 task를 수행할 수 있다.
단점
•
Real image임에도 불구하고, background가 한정적이다. (ImageNet 등 대비)
•
Spatula를 사용하는 등의 complex skill은 아직 잘 못 한다.
•
Test time에 computation이 많이 필요하다.
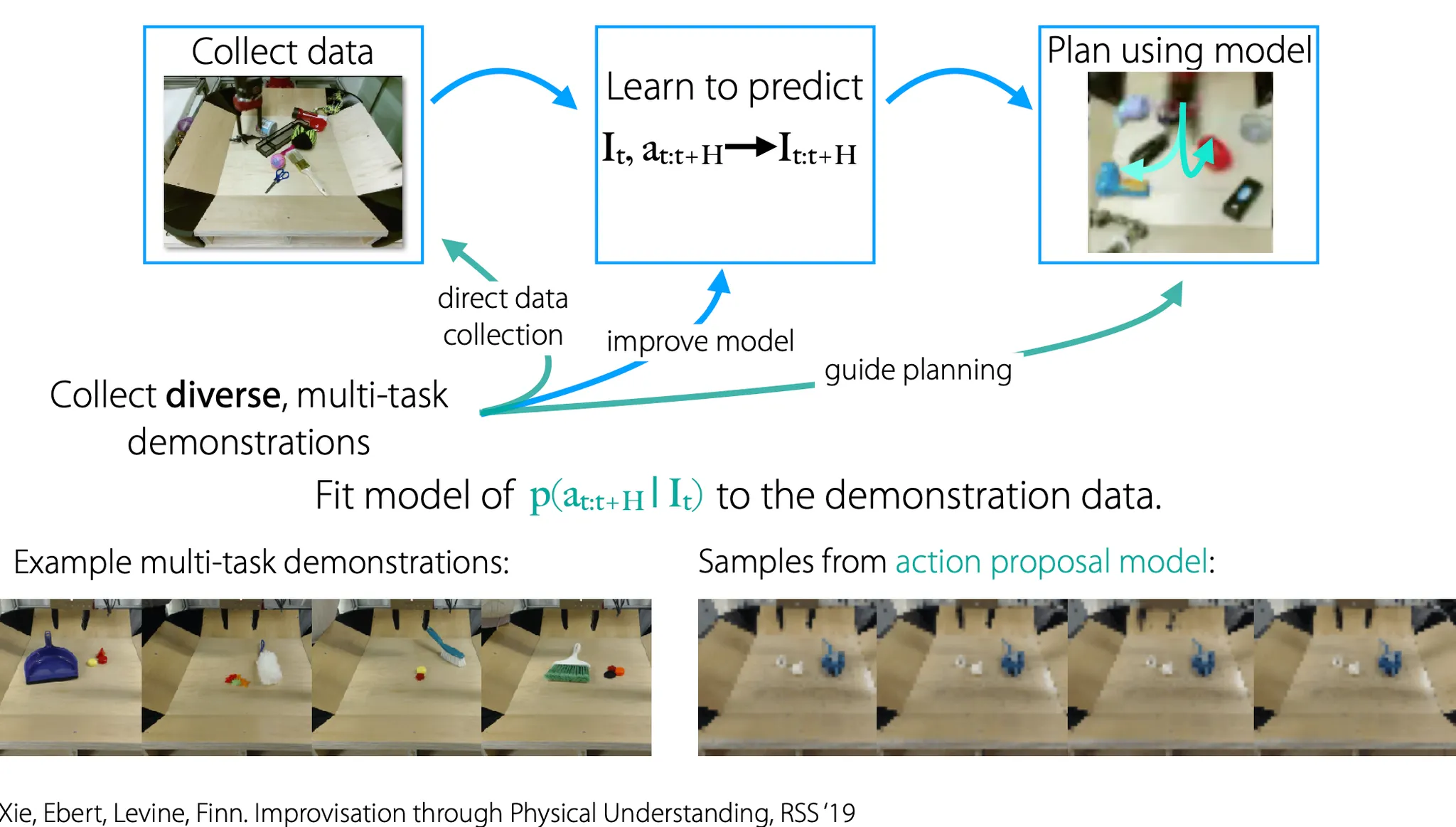
Supervision의 형태로 demonstration을 해줄 수 있음?



세 번째 접근으로는 다른 quantity를 prediction하는 방법이 있다.
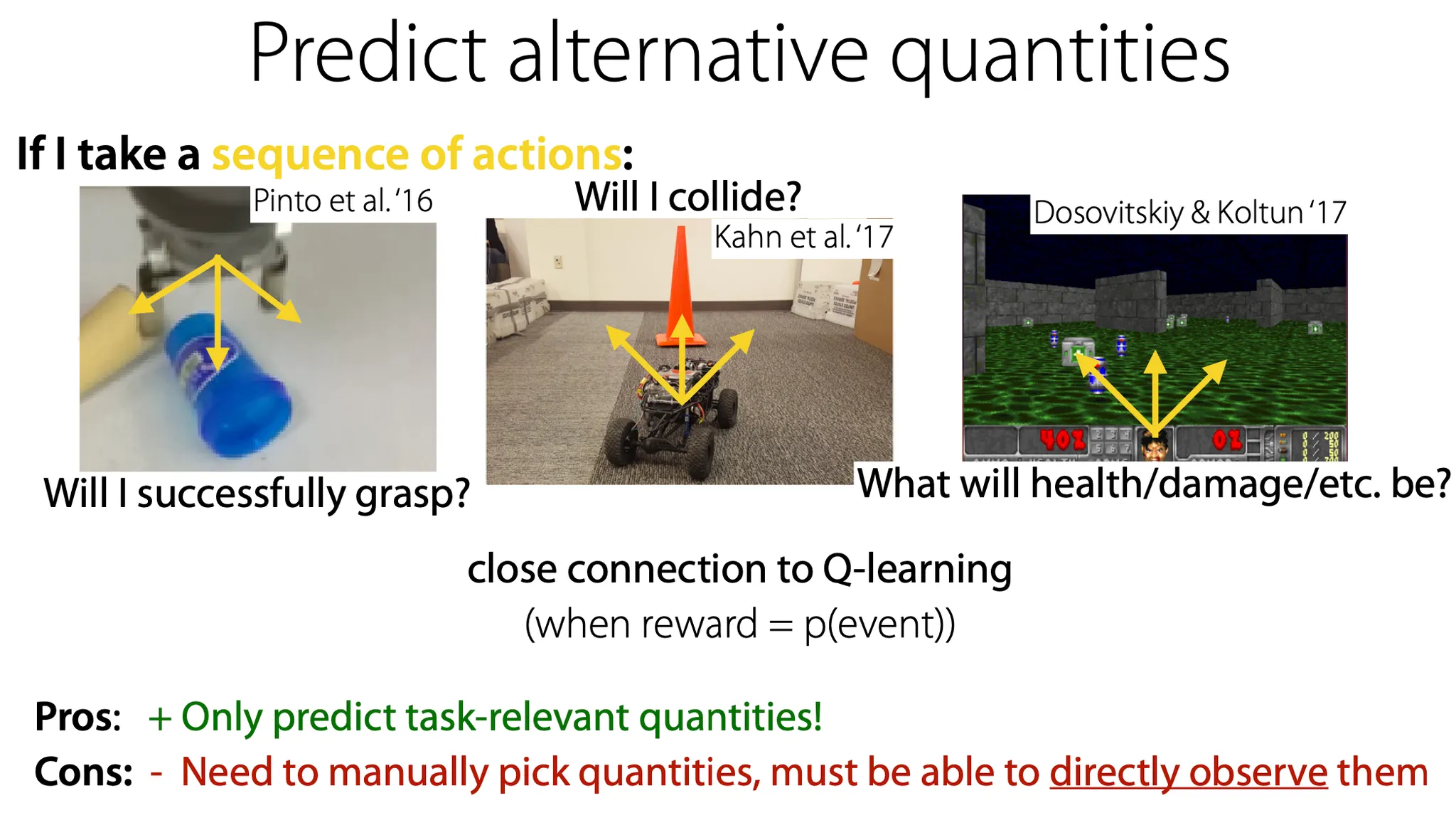
input과 동일한 형태의 data(image 등)를 generate 하는 것이 아니라, 어떤 결과를 예측하게 할 수 있다. 최종 결과를 예측하는 것이고, 그것이 reward 형태로 정의될 수 있다는 점에서 Q-learning과 연관이 깊다.
이 방법의 장점은 task에 관련된 특성만 예측하면 된다는 점이다. 단점은 그 quantity를 수동으로 설정해줘야하고, 그것이 직접 관찰할 수 있어야 한다는 점이다. 예를 들어, 사람의 감정 등은 직접 관측이 안 되므로 이 방법을 적용하기 어려울 수 있다.
Model-based meta-RL
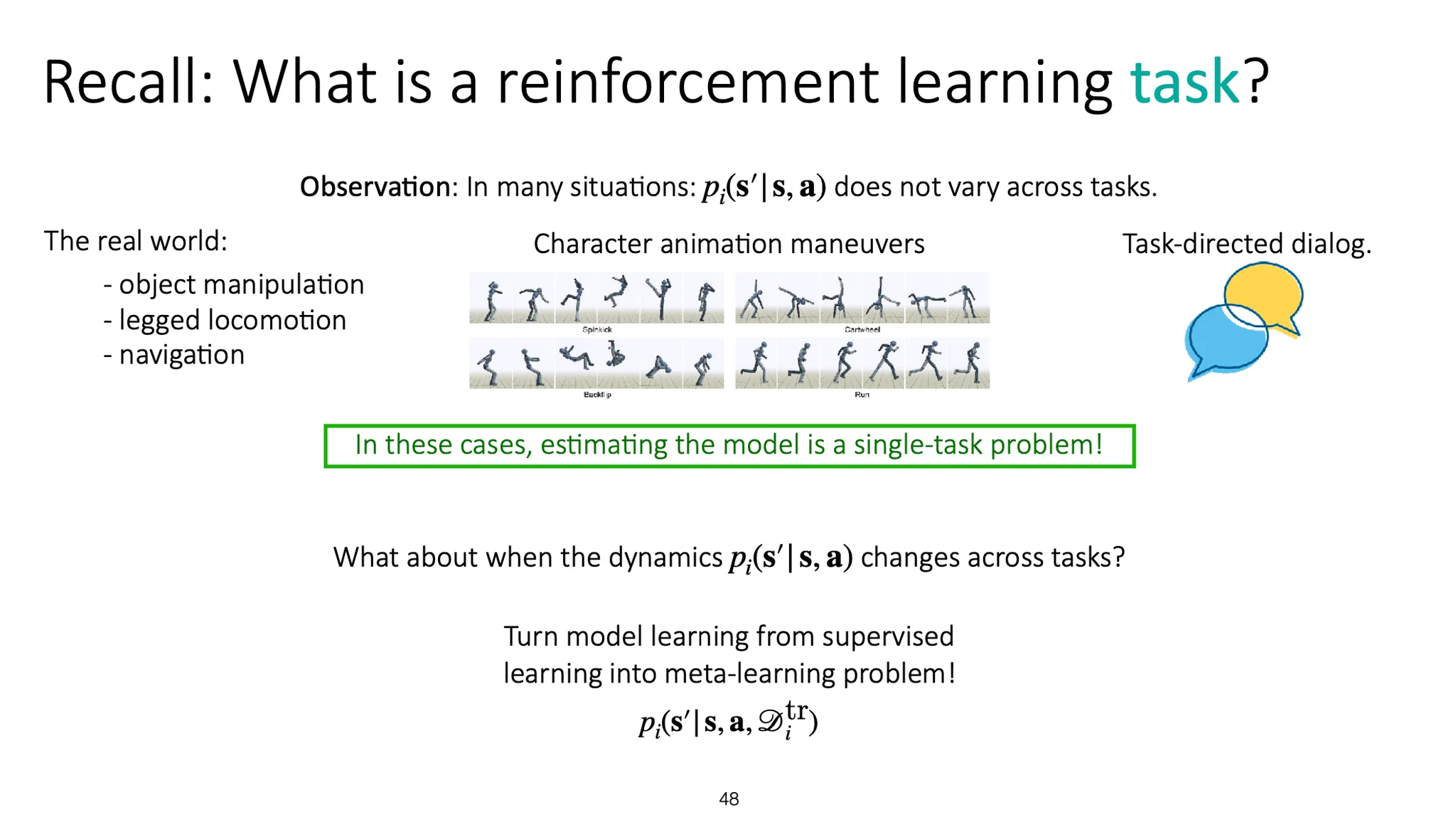
Reinforcement learning recap을 해보자.
많은 RL task들의 경우 dynamics 는 task가 바뀌어도 달라지지 않는다. 이 경우에 model을 학습하는 것은 single-task problem이라고 할 수 있다.
하지만 dynamics가 task 마다 다른 경우는 어떨까? 이 상황이 바로 meta-learning problem이다.
이전에 논의했던 meta-learning 방법들이 적용될 수 있다. LSTM이나, memory를 사용하는 방법 등..
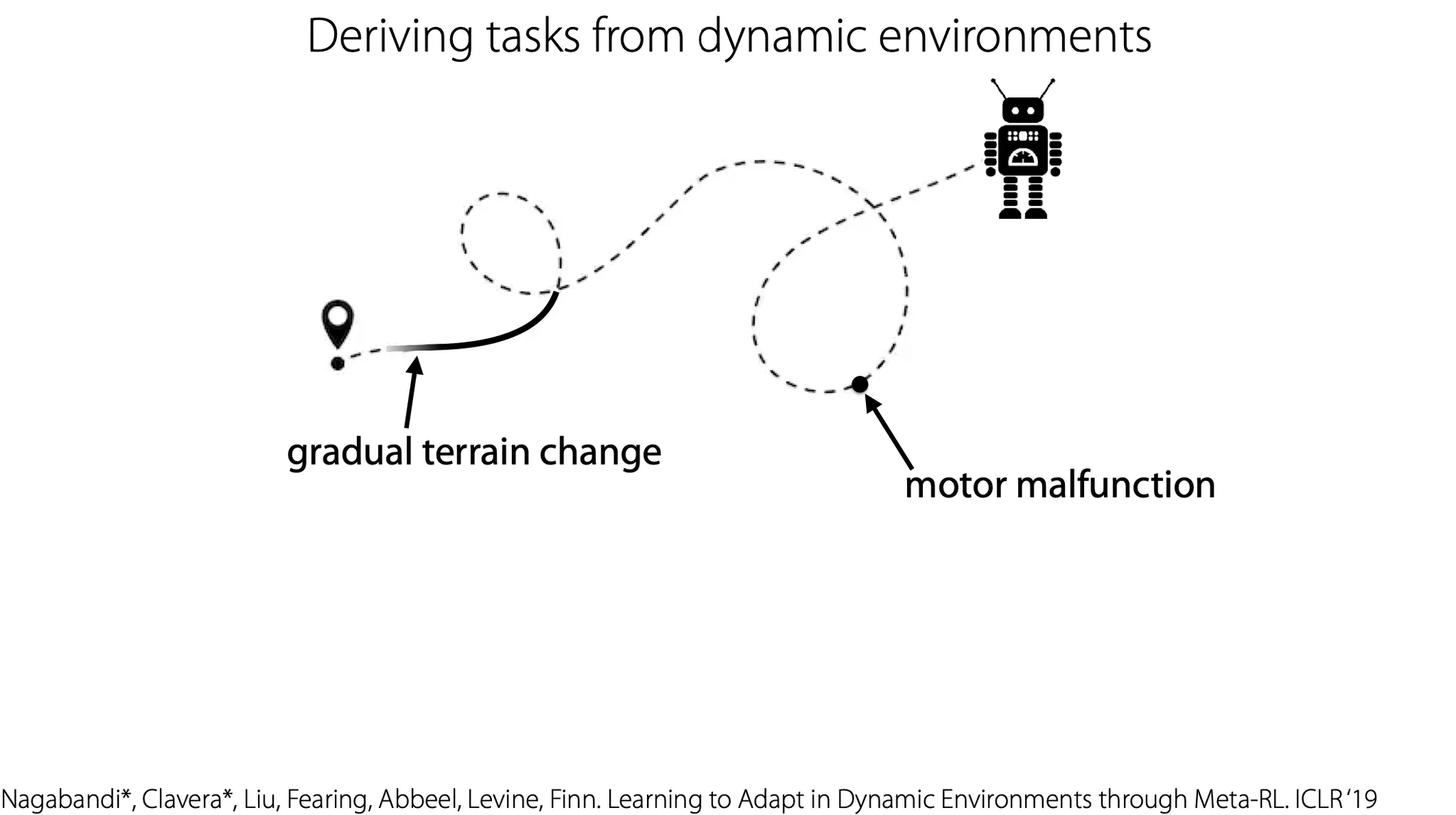
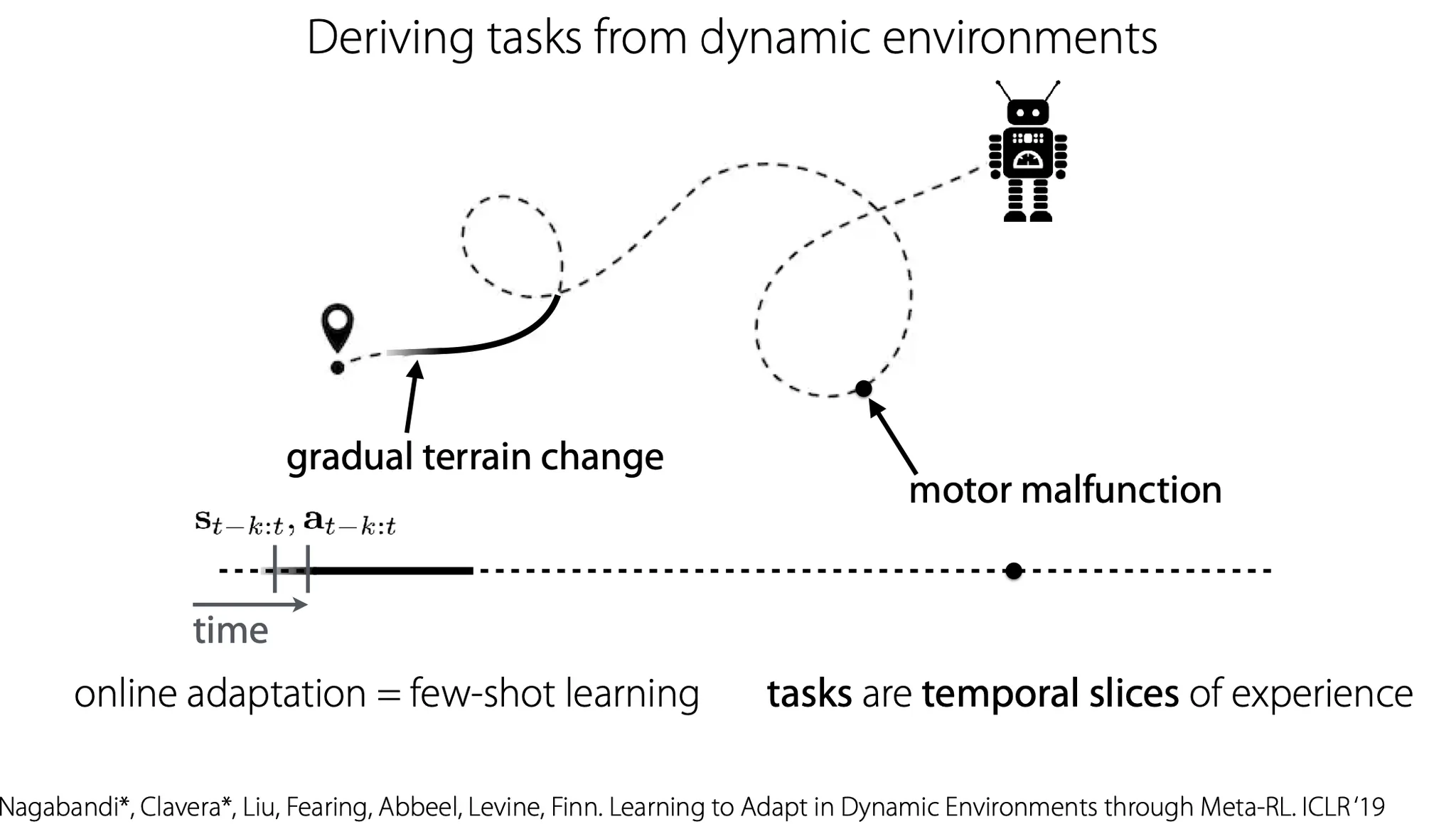
즉, terrain change나 motor malfunction 같은 dynamics에 변화가 있는 상황에서, 각 time step마다 주어진 data를 사용해 adaptation을 하는 것이라고 볼 수 있다.
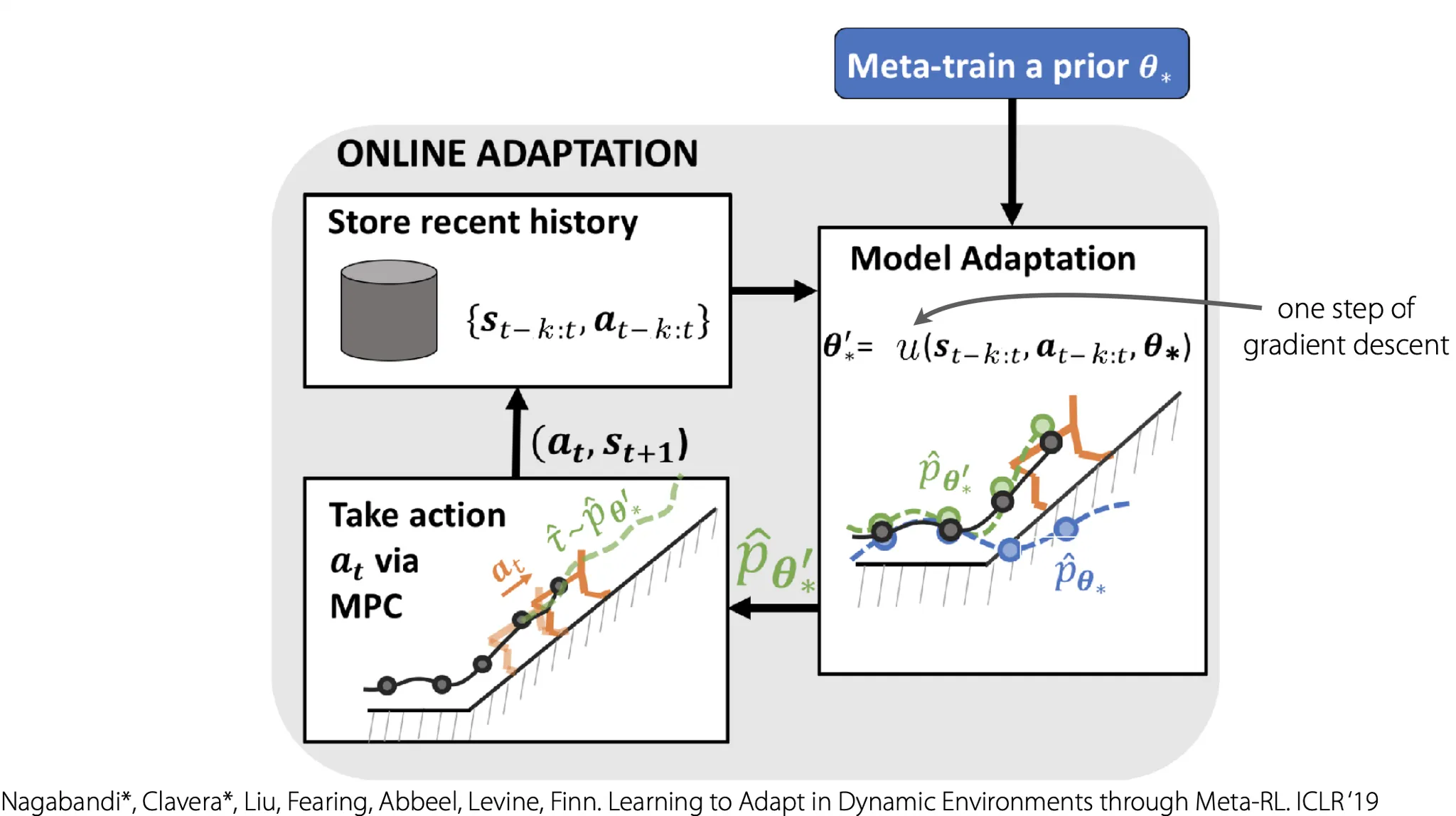
Online adaptation을 한 눈에 정리하자면, 최근 history를 저장하고, 그에 대해 adaptation을 한 뒤, 특정 action을 취하고, 그걸 다시 history에 반영한다. 이때, model 초기화를 prior 로 한다면 가 일종의 meta-knowledge가 될 것 이다.




