

논문 소개
•
WSDM 2022 논문, cite 32
Abstract
•
기존의 많은 session based recommendation 연구들은 item-item transition에 집중했고, user preference를 만들 때 user historical session을 고려하지 않고 추천을 하는 문제가 있다. (user의 전체적인 선호도를 반영하지 못한다는 뜻)
•
이 논문에서 제시하는 Heterogeneous Global Graph Neural Network (HG-GNN)에서는 item transition, user-item interactions, global co-occurrence item 등의 정보를 사용하여 유저의 선호를 파악한다. (다 쓰겠다는 소리)
•
추가적으로 Personalized Session Encoder를 통해서 global user preference (전체적인 유저 선호도)와 temporal user interest (최근 유저 선호도)를 둘 다 반영하는 시도를 했다.
Introduction
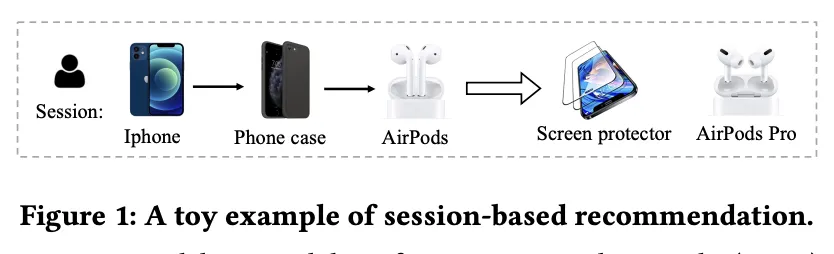
기존 방식의 문제점
1.
위의 그림처럼 비슷한 session을 가지는 유저 (아이폰, 아이폰 케이스, 에어팟) 들에게는 똑같은 추천을 하게 된다. 하지만 유저의 session이 비슷하더라도 유저의 선호도는 다를 수 있다.
2.
다른 유저의 item-item transition은 고려하고 있지 않는다. → 단일 session에 대한 유저 preference를 만들 때 정보가 부족함.
Related Works
생략
Preliminary
→ 아이템
→ 유저
→ 의 모든 history 정보
는 의 번째 session
Methodology

•
user-item edge를 추가해 user preference를 잡고자 함
•
item-item transition 이 있는 경우 edge로 만들었고, global co-occurence를 바탕으로도 비슷한 item pair를 연결하였다. (global co-occurence?)
1.
Heterogeneous Global Graph Construction
1.1. item-to-item
•
transition의 종류에는 하나의 session에서 인접하여 나타난 아이템 쌍을 의미할 수도 있고, 같은 session에서 반복적으로 같이 등장한 아이템 쌍을 의미하기도 한다.

Session-based Recommendation with Graph Neural Networks
•
인접한 item transition relation은 다른 session based GNN 논문의 방식을 따라했다함.
◦
또는 으로 표현되며 각 아이템에 대해서 top-S 개의 relation score
를 가지는 edge 들만 선택한다.
→ 만약 특정 아이템 (인기 상품) 이 다른 아이템과 연결된게 많다면 해당 아이템은 relation score가 낮게 나올 것이다. (1/neightbor 수로 계산)
→ 인기 상품들이 추천되는 것이 아니라 실제로 강하게 relation이 있는 아이템 쌍만을 반영할 수 있지 않을까 생각이 들었음
•
co-occurrence item-item pair의 경우 특정 아이템 가 있을 때 해당 아이템과 가장 자주 같이 등장하는 top-k 아이템들을 고르는 것이다.
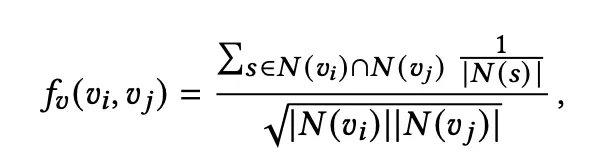
◦
의 경우 가 있는 session의 set을 의미한다.
◦
이 점수를 통해 top-K의 neighbor node를 고른다.
◦
또한 첫번째로 구하는 adjacent relation과 co-occurence relation이 겹치는 경우가 발생한다.

◦
top-K 아이템(co-occurence relation)과 adjacent relation으로 얻는 edge를 비교하여 adjacent relation으로 얻은 아이템 수만큼 top-K 아이템(co-occurence relation item)을 자른다.
◦
similar relation에 노이즈가 너무 많이 들어가는 것을 방지하기 위함
1.2. item-to-user
•
item-user relation의 경우 user의 long-term preference를 나타내기 위해 필요하다.
•
user item interaction이 있는 경우 또는 로 edge를 나타낸다.
2.
Heterogeneous Global Graph Neural network
•
유저 벡터와 아이템 벡터는 똑같이 d 차원의 embedding vector로 초기화
◦
, → 초기값
◦
, → k layer 이후 embedding vector
•
아이템의 경우 가능한 relation은 등이 있다. 각각의 relation을 로 두고 다음과 같이 neighbor aggregation이 가능하다.
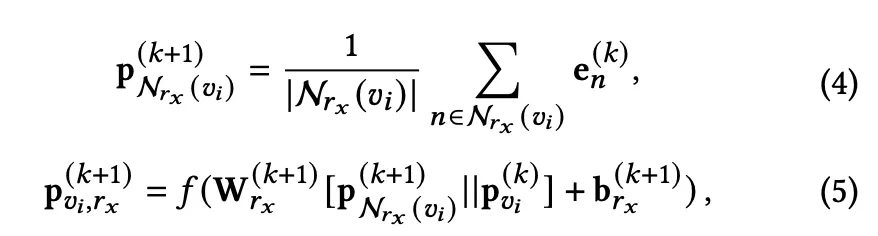
•
은 k+1 번째 layer에서 아이템 와 relation을 가지고 있는 neighbor node들을 aggregate 한 결과라고 보면 된다.
•
는 또는 로 neighbor node들의 representation vector를 나타낸다.
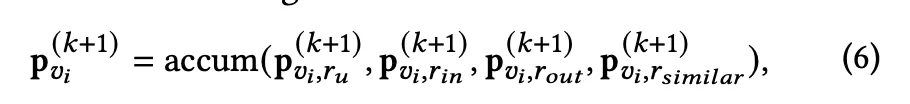
•
최종적인 은 위에서 구한 다양한 relation의 representation vector를 합친다. sum, stack, mean 중에서 모든 정보를 골고루 반영하기 위해 mean을 사용하였다고 한다.

•
유저 representation vector의 경우 밖에 없으므로 위와 같이 합쳐진다.

•
최종 representation vector는 위와 같이 표현되며, 실험적으로 의 uniform 값을 사용한다고 한다. (lightgcn과 똑같은 결과)
3.
Personalized Session Encoder
•
추천을 할 때 current session 도 중요하지만 long-term user preference도 중요하다. General Preference Learning 모듈과 Current Preference Learning 모듈을 만들었음
•
Current Preference Learning
◦
user의 session이 일 때, positional embedding을 더한 item representation을 soft attention에 통과
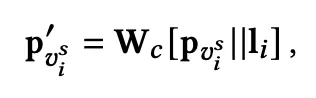

◦
는 global representation으로전체 아이템에 representation에 대한 평균, 전반적인 representation 정보를 학습하기 위해 사용한다.

◦
를 각각의 아이템마다 구하게 되는데, 이때 각 아이템의 representation과 global represenation을 사용한다.
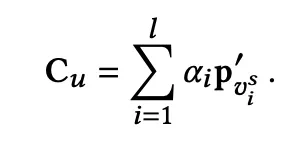
◦
current preference는 각각의 representation에 위에서 구한 soft-attention 가중치를 곱하게 된다.
•
General Preference Learning
◦
general preference embedding을 구할 때는 위처럼 모든 아이템들을 평균내서 구한 global representation이 아니라 HGNN을 통해서 얻어낸 user representation을 이용한다.


◦
계산 방식은 동일함

•
두 preference는 weighted sum되어 하나의 preference representation으로 나타내어 진다.
4.
Prediction and Training

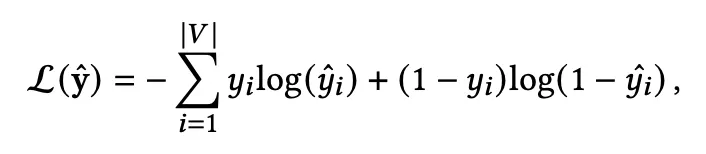
•
위에서 구한 representation vector와 item embedding을 각각 내적하여 해당 아이템을 다음에 클릭할 확률로 나타냄
Experiments
사용한 데이터셋

모델간 비교

•
몇개의 데이터셋에서는 성능이 살짝 떨어지지만 대체적으로는 가장 높다.
•
생각보다 엄청 좋진 않음,,,
Ablation Study
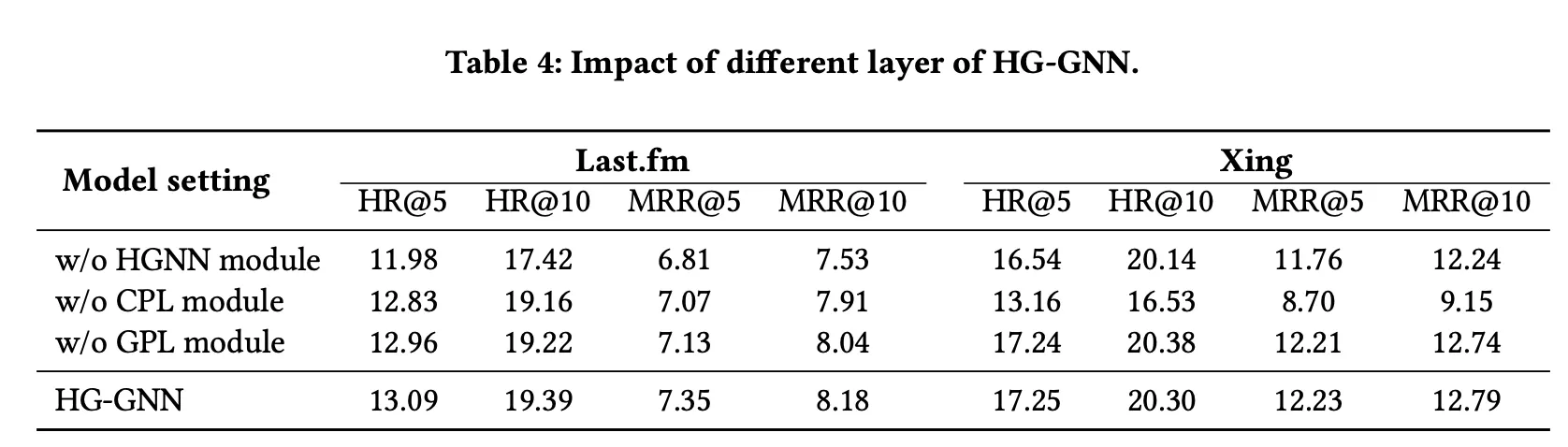
•
HGNN을 완전히 없앤 경우, CPL (current preference) 모듈을 없앤경우, GPL (general preference learning)을 없앤 경우 위의 결과와 같다.
•
생각보다 GPL은 영향이 적고 상대적으로 CPL을 뺐을 때 영향이 큰 것 같음

•
여러가지 종류의 relation edge들을 제거했을 때 결과이다.
→ 생각했던 것보다 영향이 적음, 심지어 similar edge를 제거하는 경우 MRR이 오른다 …?
→ MRR이 오른다는 것은 정답 아이템을 상위권으로 잘 올린다는 것인데, HG-GNN을 적용하면 candidate item은 잘 뽑지만 ranking은 잘하지 못한다는 생각이 들었음


•
각각 adjacent edge sampling size, similar item edge top-K 에 대한 실험이다.
결론
다양한 방식으로 그래프 edge를 만들어서 정보를 넣으려고 한 것 같다. 하지만, 너무 많은 정보를 넣어서 오히려 노이즈도 많이 학습되어 성능이 생각보다 뛰어나지 않은 건가 생각이 들었다.