

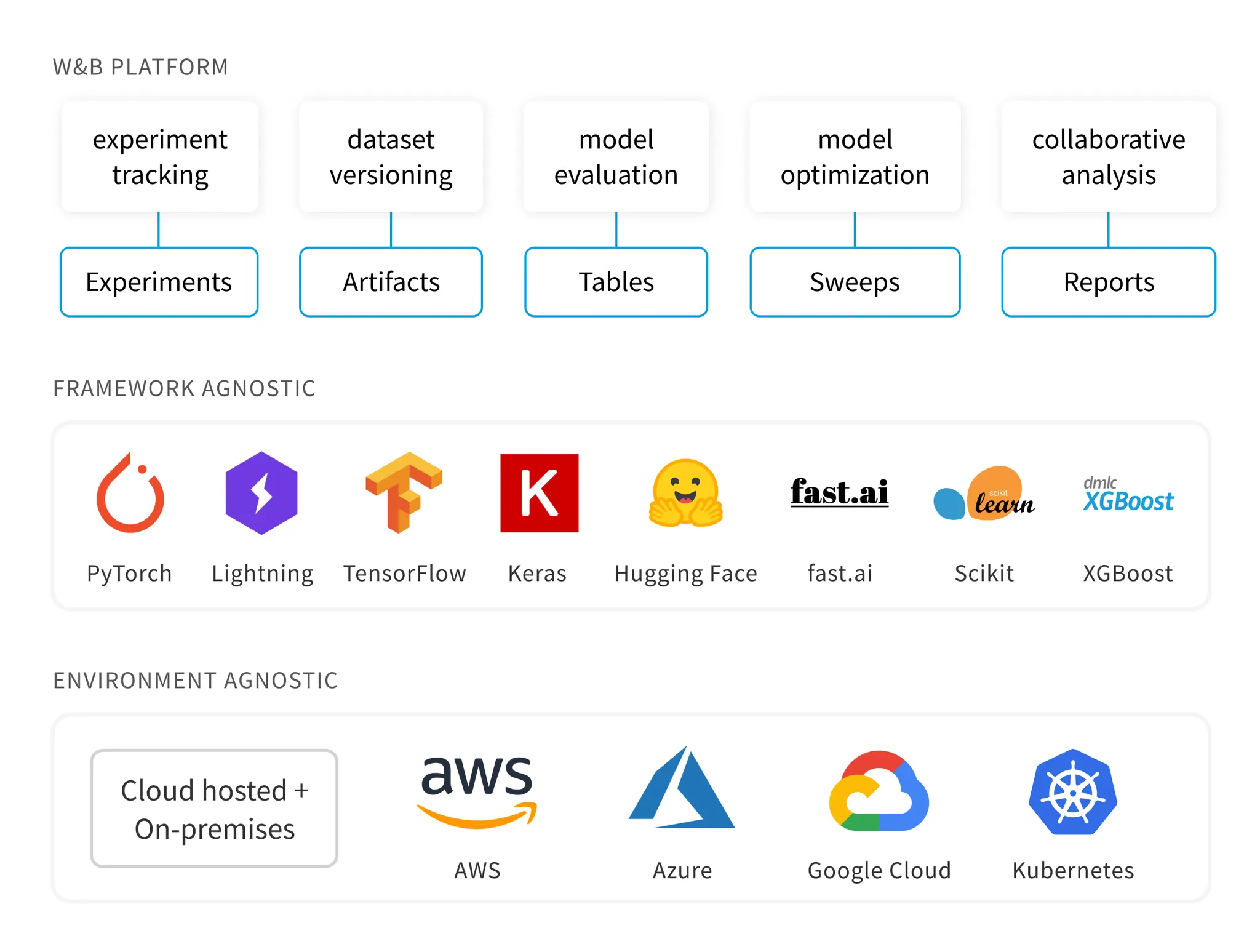

Introduction
모델 학습 시 학습 현황 monitoring, hyperparameter tuning 등 다양하게 활용되는 tool인 wandb에 대해 정리한 내용입니다.
Example code github



Why wandb?
1.
Train/Validation/Test logging
2.
Visualization (log, gradient, …)
3.
Hyperparameter tuning
Installation
$ conda install -c conda-forge wandb
# or
$ pip install wandb
Bash
복사
Synchronization
1.
Sign up in Weights and Biases
2.
login in your local env
$ wandb login
Bash
복사
Paste your API key from wandb website.
Initiation
import wandb
wandb.init(project='project_name',
entity='user_name or team_name',
name='display_name_for_this_run')
# or
wandb.init(project='project_name')
wandb.run.name = 'disply_name_for_this_run'
wandb.run.save()
Python
복사
Experiment tracking
Track metrics
Major use case of wandb.
wandb.log
for epoch in range(1, args.epochs+1):
print(f'=====Epoch {epoch}')
print("Training...")
train_mae = train_utils.train_model(model, device, train_loader, criterion, optimizer)
print("Evaluating...")
valid_mae = train_utils.evaluate_model(model, device, valid_loader, metric='mse')
print({'Train': train_mae, 'Valid': valid_mae})
wandb.log({'epoch': epoch,
'train_loss': train_mae,
'valid_loss': valid_mae})
Python
복사
Can track & visualize various metrics per epoch.
wandb.watch
model = Net()
wandb.watch(model, criterion, log='all')
Python
복사
Can track & visualize model’s gradients and topology per epoch.
Also can view system dashboard including..
•
CPU
•
GPU
•
Memory uilization
•
Power usage
•
Temperatures
•
…
Can explore all different runs in a single dashboard.
Track hyperparameters
wandb.config
parser = argparse.ArgumentParser()
parser.add_argument('--device', type=int, default=0)
...
args = parser.parse_args()
wandb.config.update(args)
# or
config = wandb.config
config.learning_rate = 0.01
config.device = 0
Python
복사
Can view all runs with their hyperparameters.
Visualize model
With the watch command, we can inspect the model’s topology (network type, number of parameters, output shape, …)
Inspect logs
We can also see actual raw logs printed in the console.
Data and model versioning
W&B has a built-in versioning system.
Artifact is a versioned folder of data and used for dataset versioning, model versioning and dependencies tracking.
artifact = wandb.Artifact('cifar10', type='dataset')
file_path = './data/cifar-10-batches-py'
artifact.add_dir(file_path) # or artifact.add_reference('reference_url')
# to save artifact
run.log_artifact(artifact)
# to load saved artifact
artifact = run.use_artifact('artifact')
artifact_dir = artifact.download()
Python
복사
Hyperparameter tuning with Sweeps
W&B Sweeps is a tool to automate hyperparameter optimization and exploration.
→ Reduce boilerplate code + Cool visualizations.
First create a configuration file
sweep_config = {
'method': 'random',
'metric': {'goal': 'minimize', 'name': 'loss'},
'parameters': {
'batch_size': {
'distribution': 'q_log_uniform',
'max': math.log(256),
'min': math.log(32),
'q': 1
},
'epochs': {'value': 5},
'fc_layer_size': {'values': [128, 256, 512]},
'learning_rate': {
'distribution': 'uniform',
'max': 0.1,
'min': 0
},
'optimizer': {'values': ['adam', 'sgd']}
}
Python
복사
Define the tuning method, metric, and parameters
•
tuning method (3 options): random, grid search, bayes search
•
metric: whether to minimize or maximize
•
parameters: hyperparameters to be searched by Sweeps.
Sweeps will try all different combinations and compute loss for each one.
def train(config):
with wandb.init(project='project_name', entity='username or teamname', config=config):
config = wandb.config
net = Net(config.fc_layer_size)
net.to(device)
criterion = nn.CrossEntropyLoss()
optimizer = optim.SGD(net.parameters(), lr=config.learning_rate)
Python
복사