

Design space of GNN

•
SOTA GNN을 사용하고 싶지만, 너무 선택지가 많다.
GNN
•
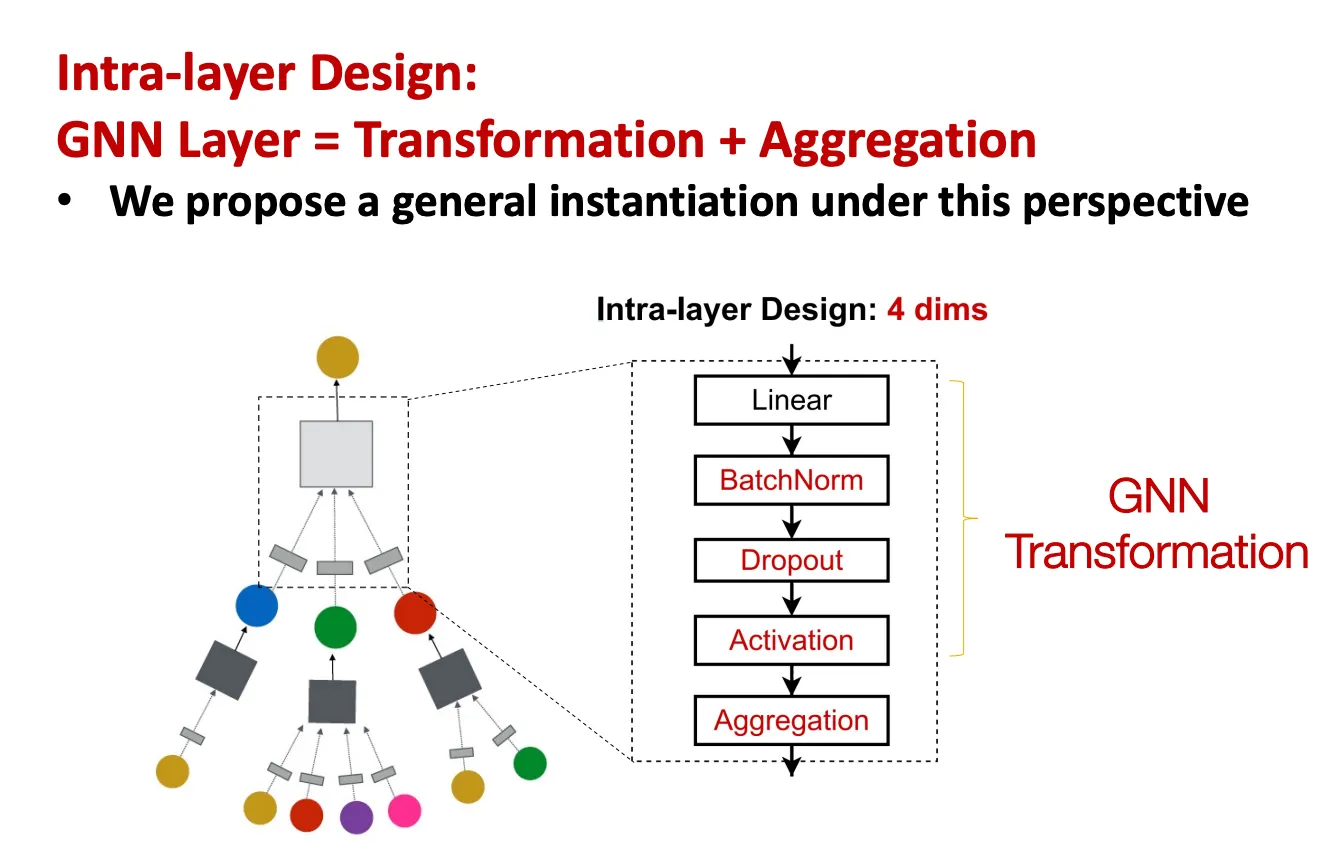
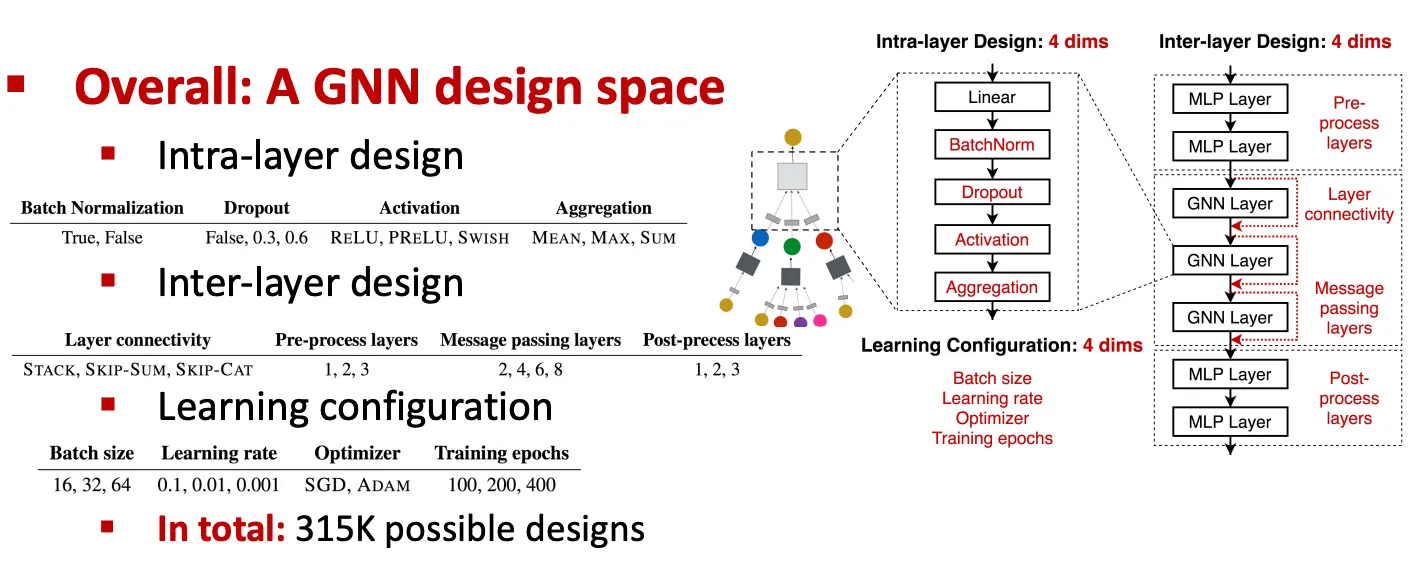
Intra-layer: Transformation + Aggregation step으로 구성
◦
그런데 BatchNorm → Activation → Dropout 이 일반적 아닌가…
•
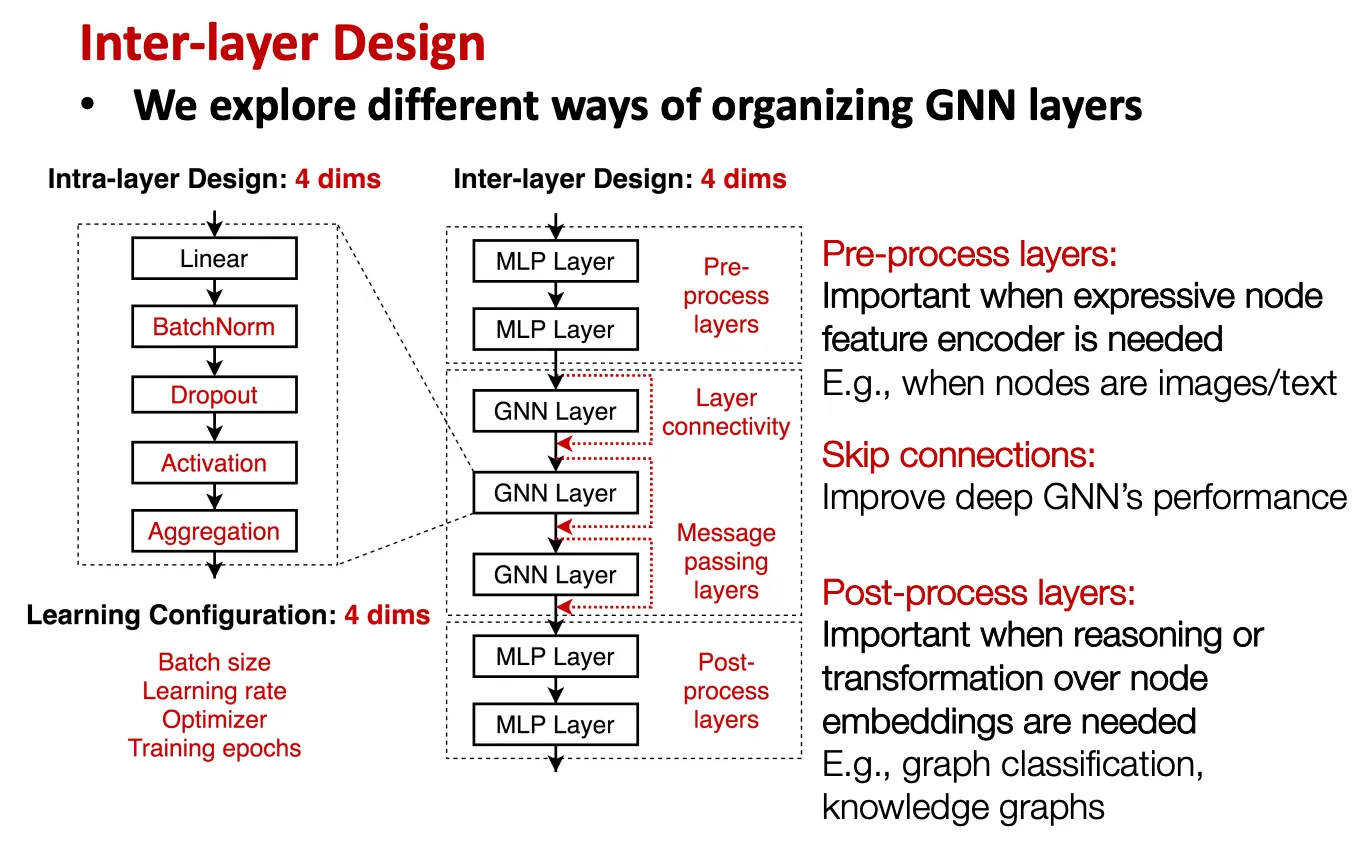
Inter-layer: Pre-processing layer, skip connection, post-processing layer 등
•
Learning configuration: paper에서는 언급이 잘 안 되지만 성능에 굉장히 중요한 영향 미친다.
◦
Batch size, learning rate, optimizer, training epochs
•
고려할 인자가 많아서 경우의 수가 combinatorial하게 증가한다.
General GNN task space

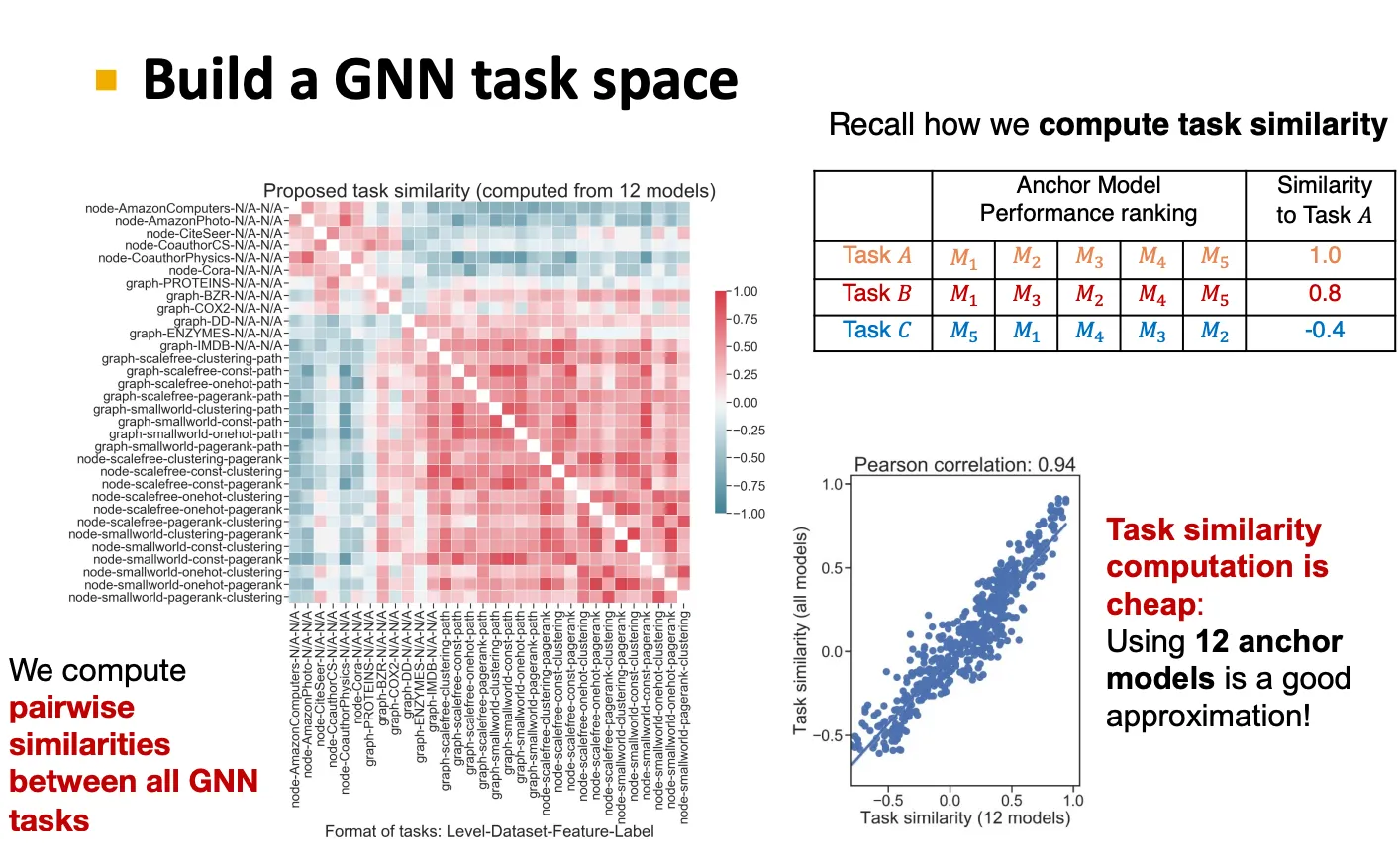
GNN task를 구분하는 방법으로 일반적으로는 node / edge / graph level로 구분하지만, 이것은 taxonomy를 구성하는데 좋은 방법은 아니다.
따라서 어떤 정량적인 task similarity metric을 만들어서, 서로 유사한 task끼리 비슷한 GNN을 사용하는 것이 좋다.
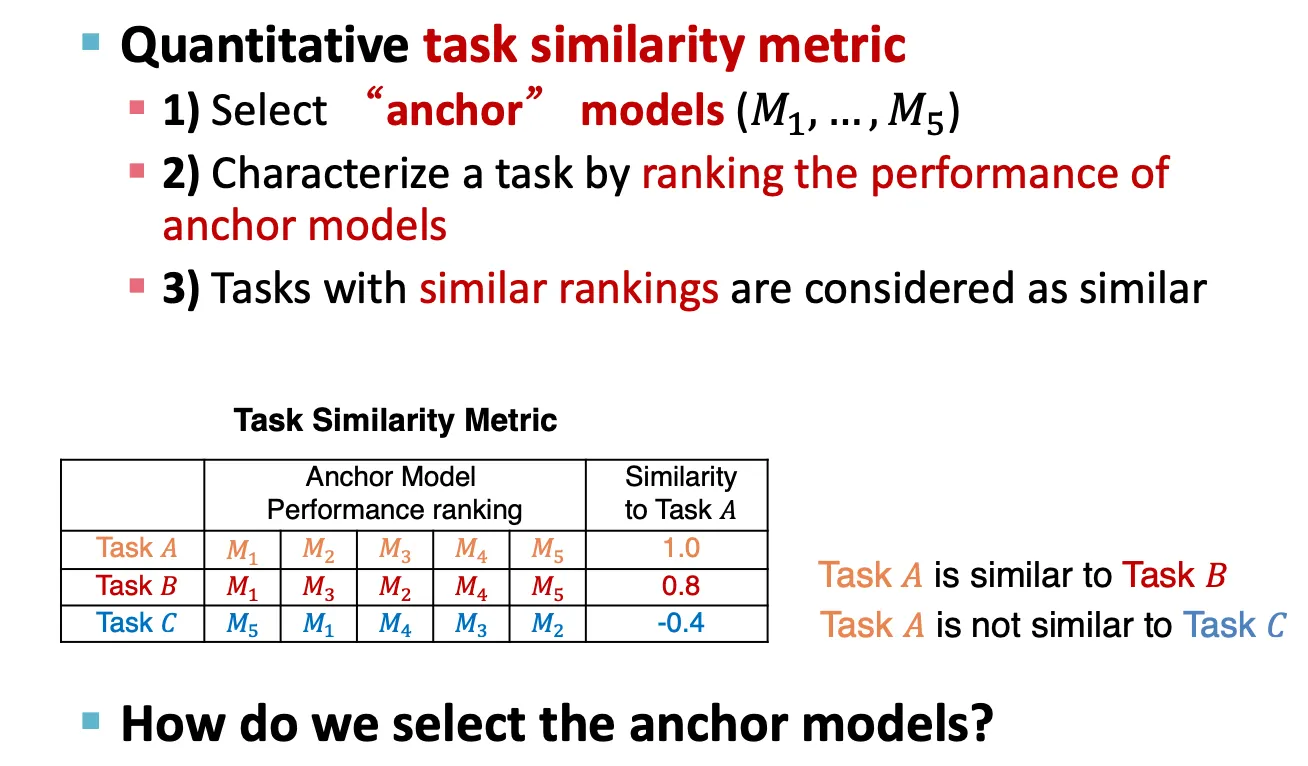
Quantitative task similarity metric
1.
먼저 anchor model들을 선정한다.
2.
그리고 그 anchor model들에 대해 task들을 ranking 한다.
3.
Ranking이 비슷한 task끼리의 similarity가 높은 것으로 간주한다.
Selecting the anchor models

1.
작은 dataset을 선택한다.
2.
N개의 model을 sample해서 dataset에 돌린다.
3.
Performance에 따라 sorting 해서 균일한 간격으로 model을 고른다.
이후 controlled random search를 통해서 평가한다.
Results1: A Guideline for GNN Design
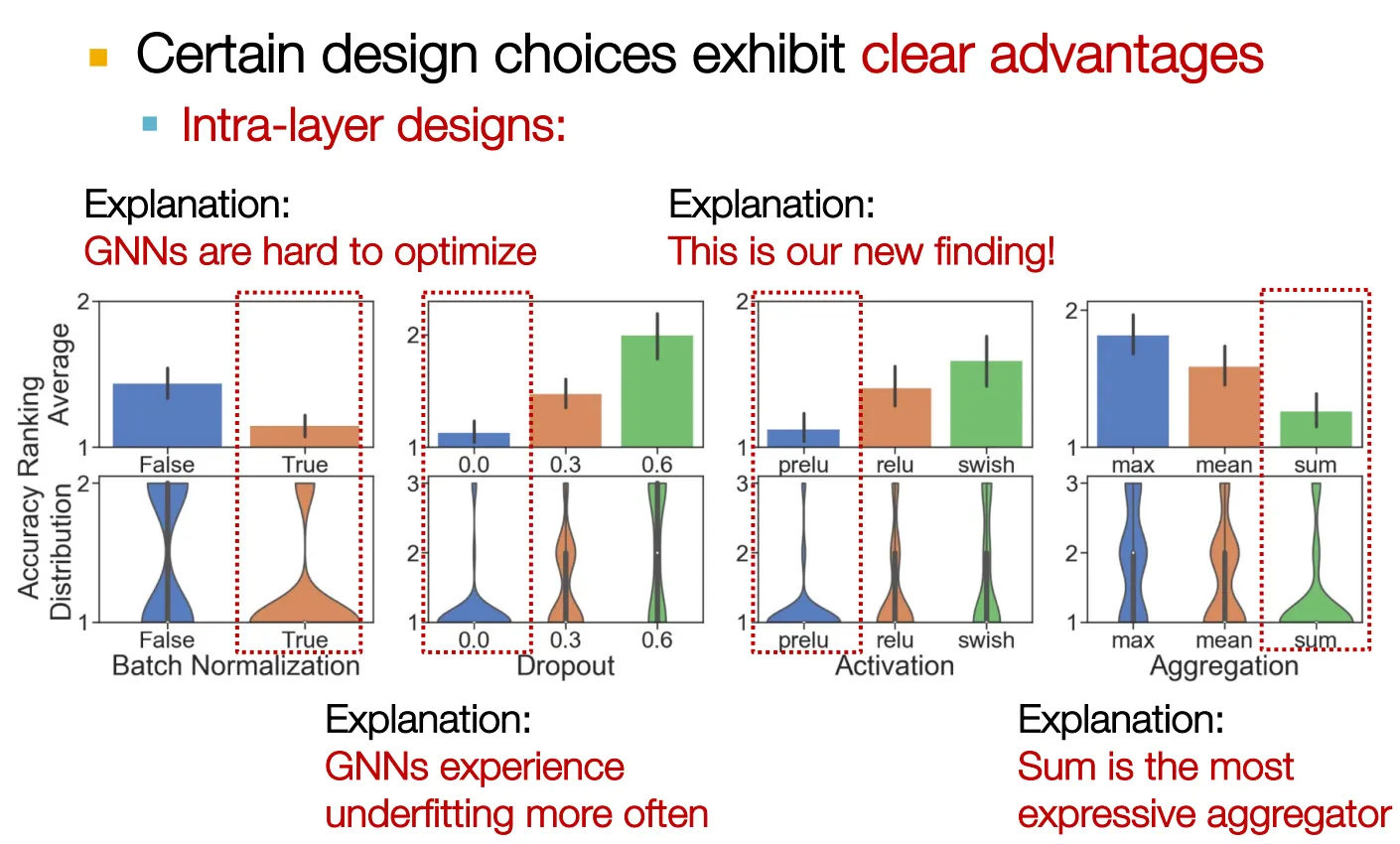
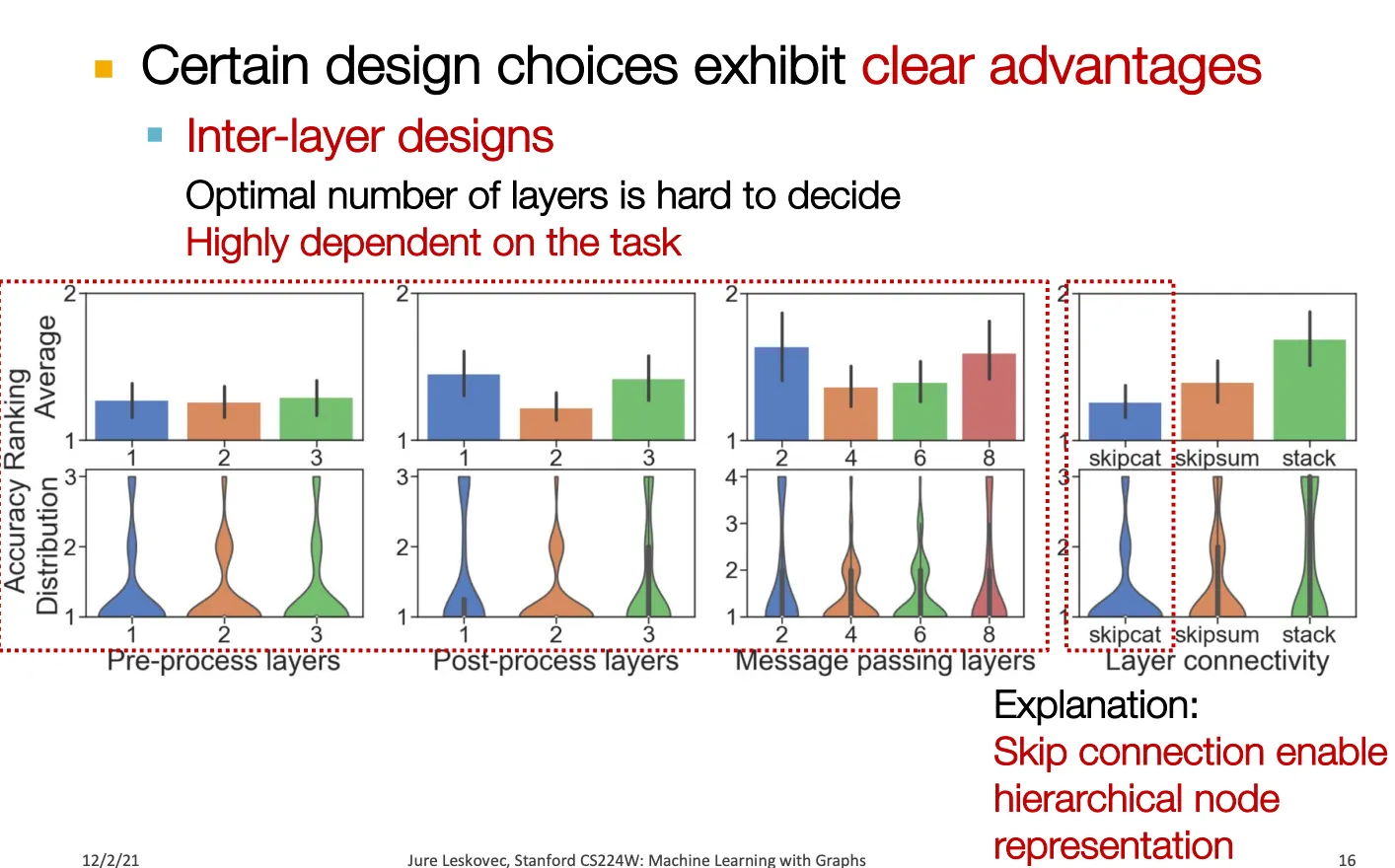
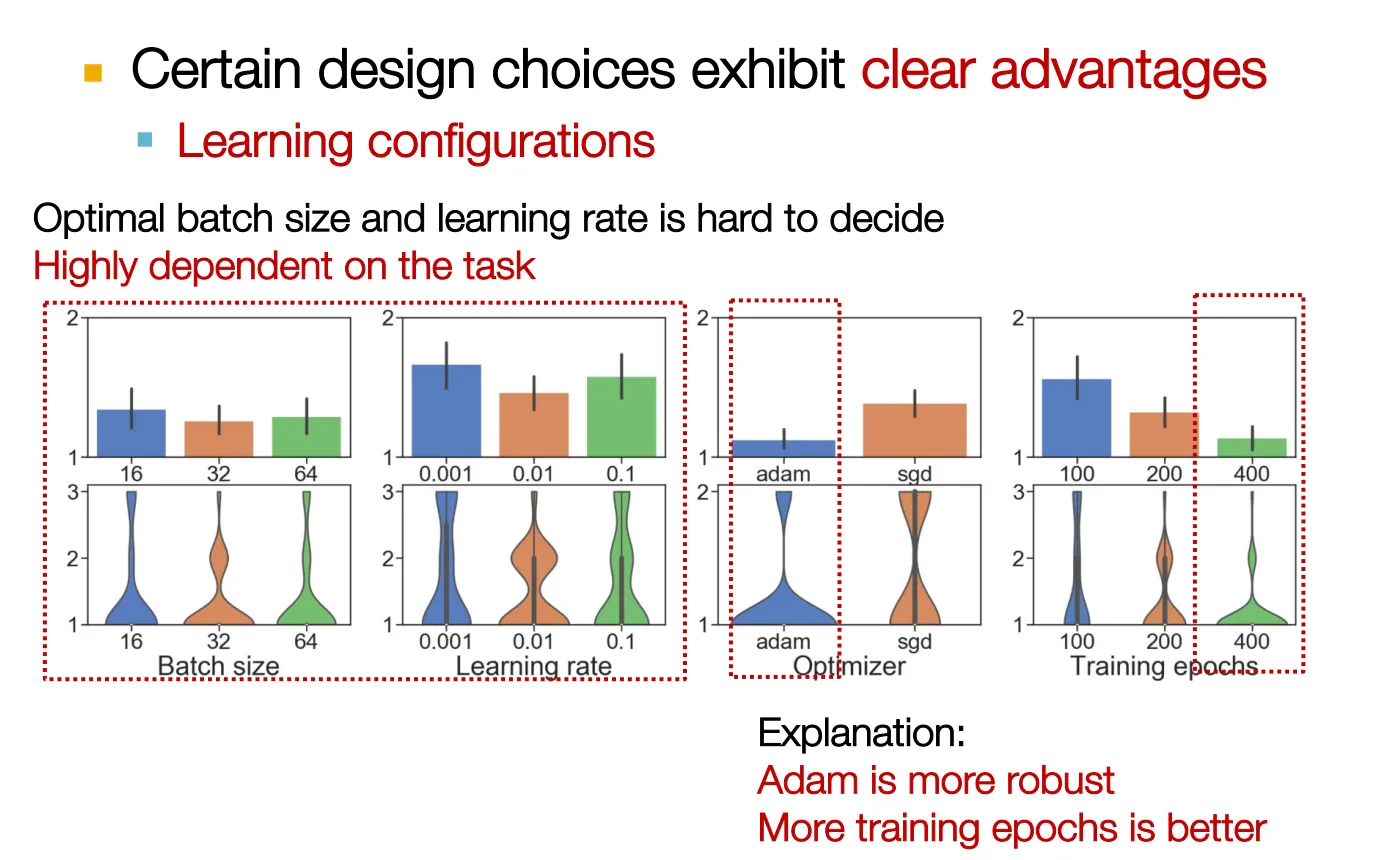
Results2: Understanding GNN Tasks
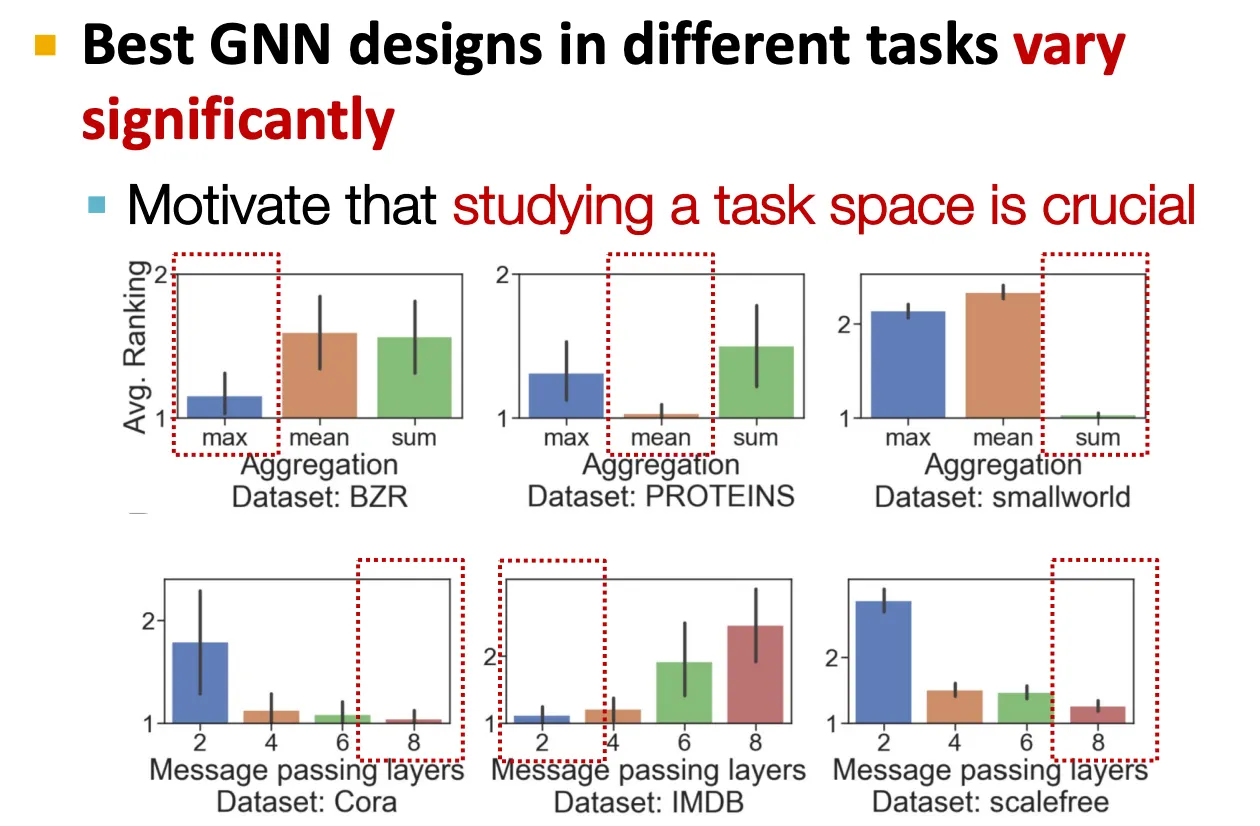
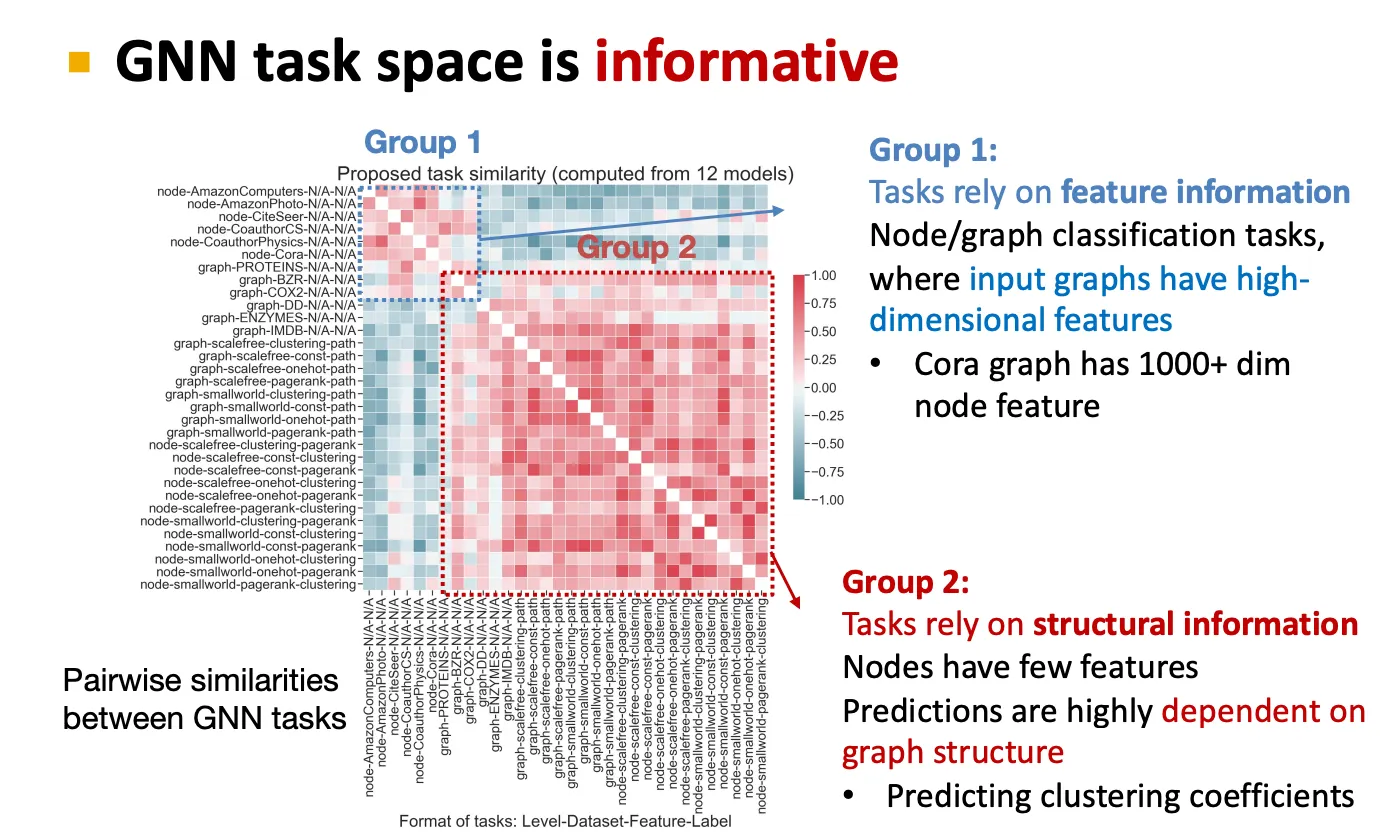
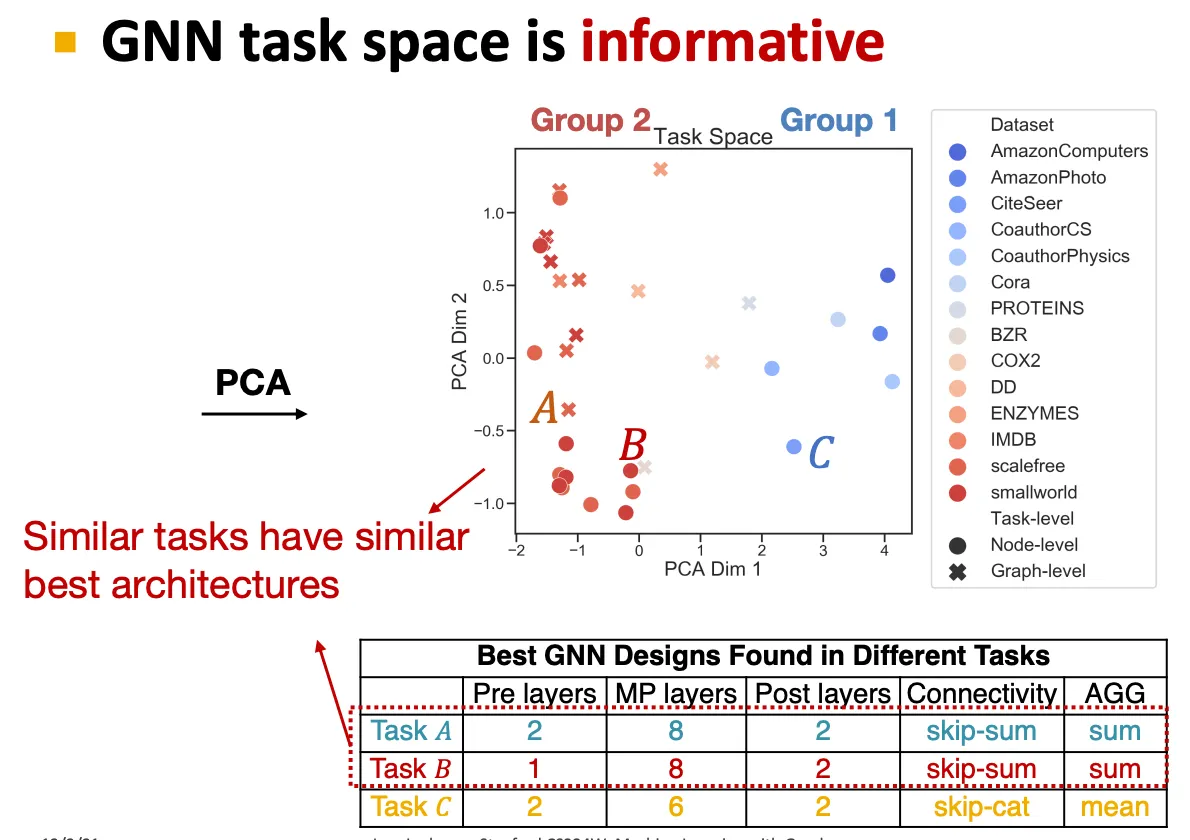
Task마다 best GNN은 좀 다를 수 있고, 이를 결정하기 위해 GNN task space를 잘 만드는 것이 중요하다.
GNN task space는 각 group마다 특징을 잡아낼 수 있다.
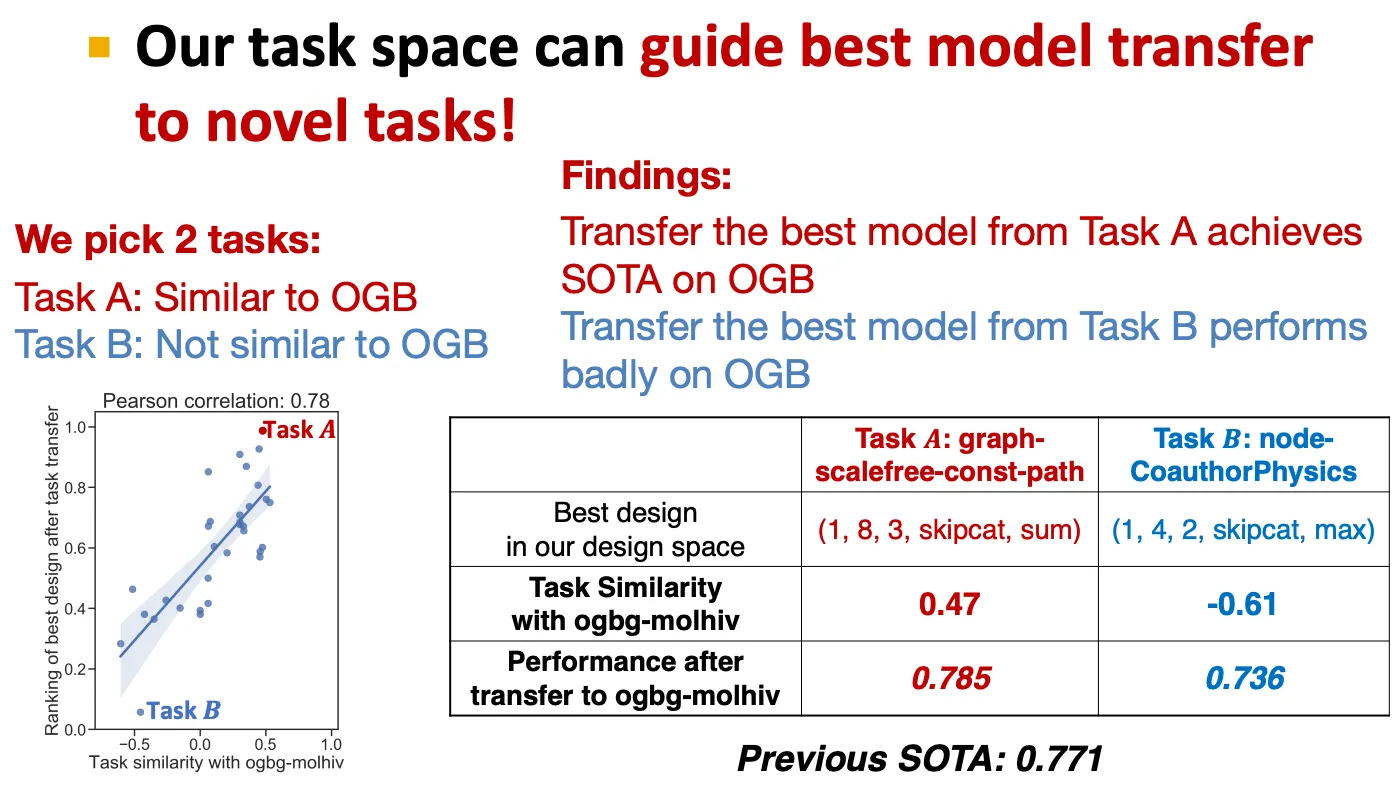
Results 3: Transfer to Novel tasks

새로운 task에 적용하는 방법
1.
12 anchor model performance 측정
2.
새로운 task와 기존의 task 간 similarity 측정
3.
비슷한 task에서 좋았던 GNN 추천
GNN Design space summary

Pre-training GNNs
Challenges of Applying ML
1.
Scarcity of labeled data
→ ML model은 작은 training data에 overfit
2.
Out-of-distribution prediction
→ ML model은 extrapolation이 잘 안 됨
특히 deep learning model은 training data 수보다 parameter 수가 더 많으므로 작은 labeled data에 overfit 하기가 더 쉽다.

Injecting Domain Knowledge
Model의 OOD prediction performance를 개선하기 위해, 어떤 domain knowledge를 모델이 학습하도록 할 수 있다.
Effective Solution: Pre-training

Data가 많이 있는, 비슷한 domain에서 pretraining을 진행하고, 원하는 downstream task에 finetune을 해볼 수 있다.
Naïve strategy
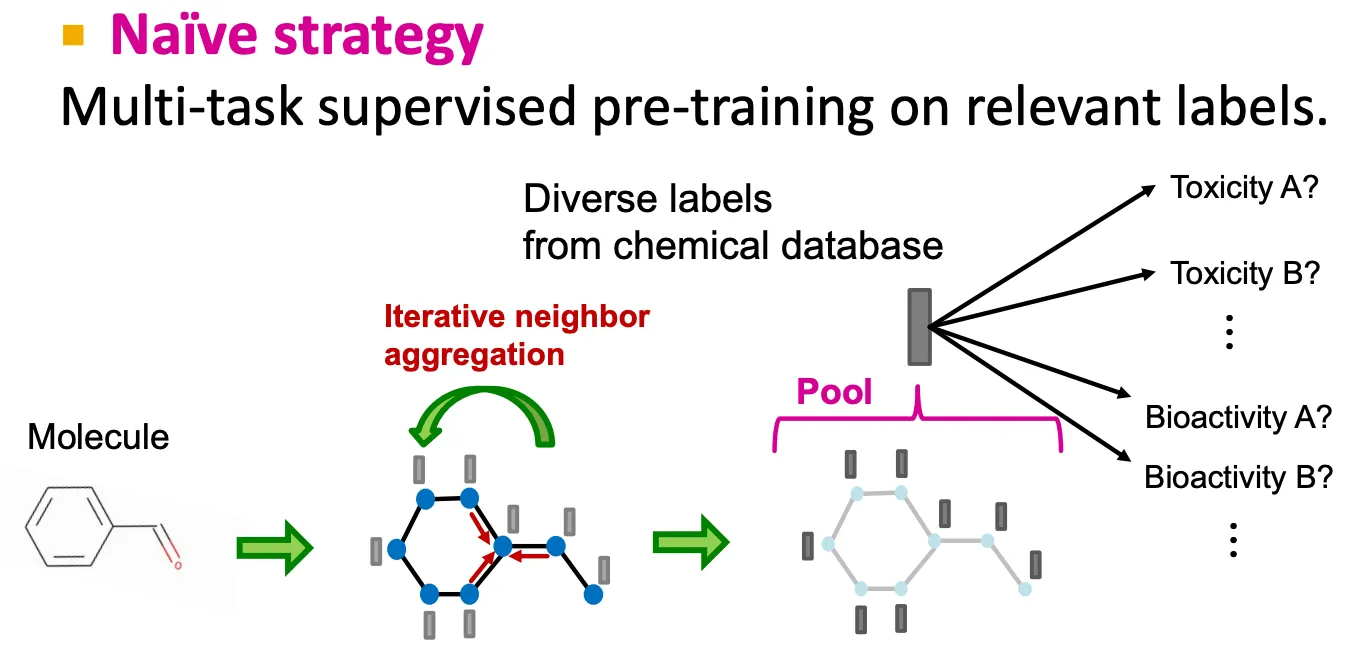
•
Naïve하게는 multi-task style로 비슷한 labeled supervised learning을 수행할 수 있다.
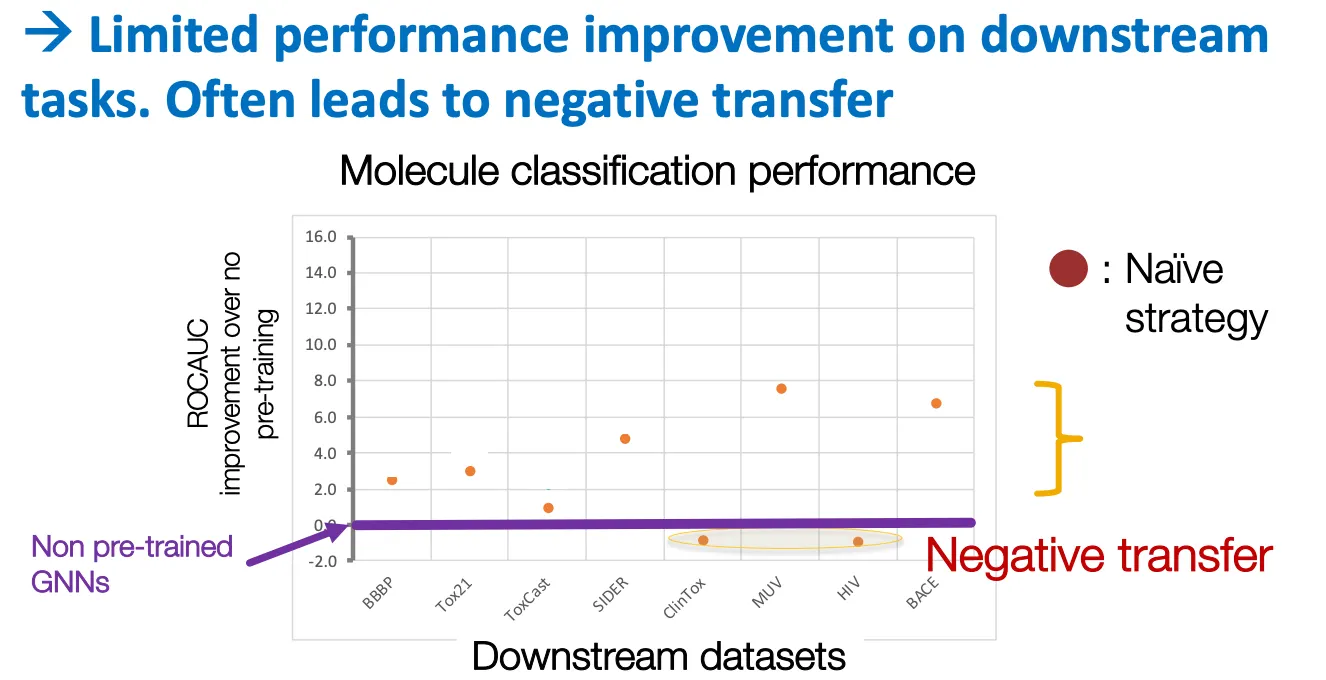
•
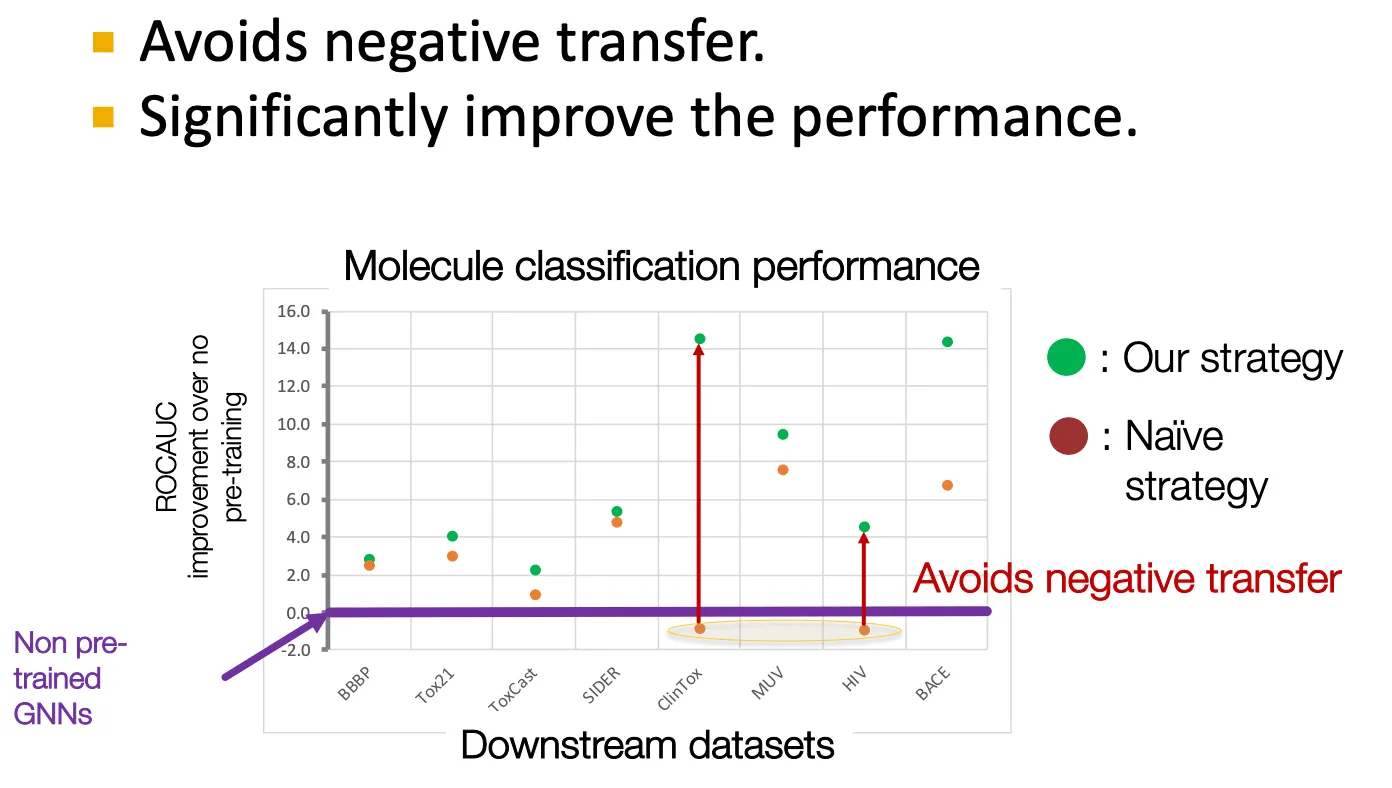
하지만 negative transfer 등의 문제가 있다.
Pretrain both node and graph embeddings
→ local 및 global structure에 대한 domain knowledge를 학습.
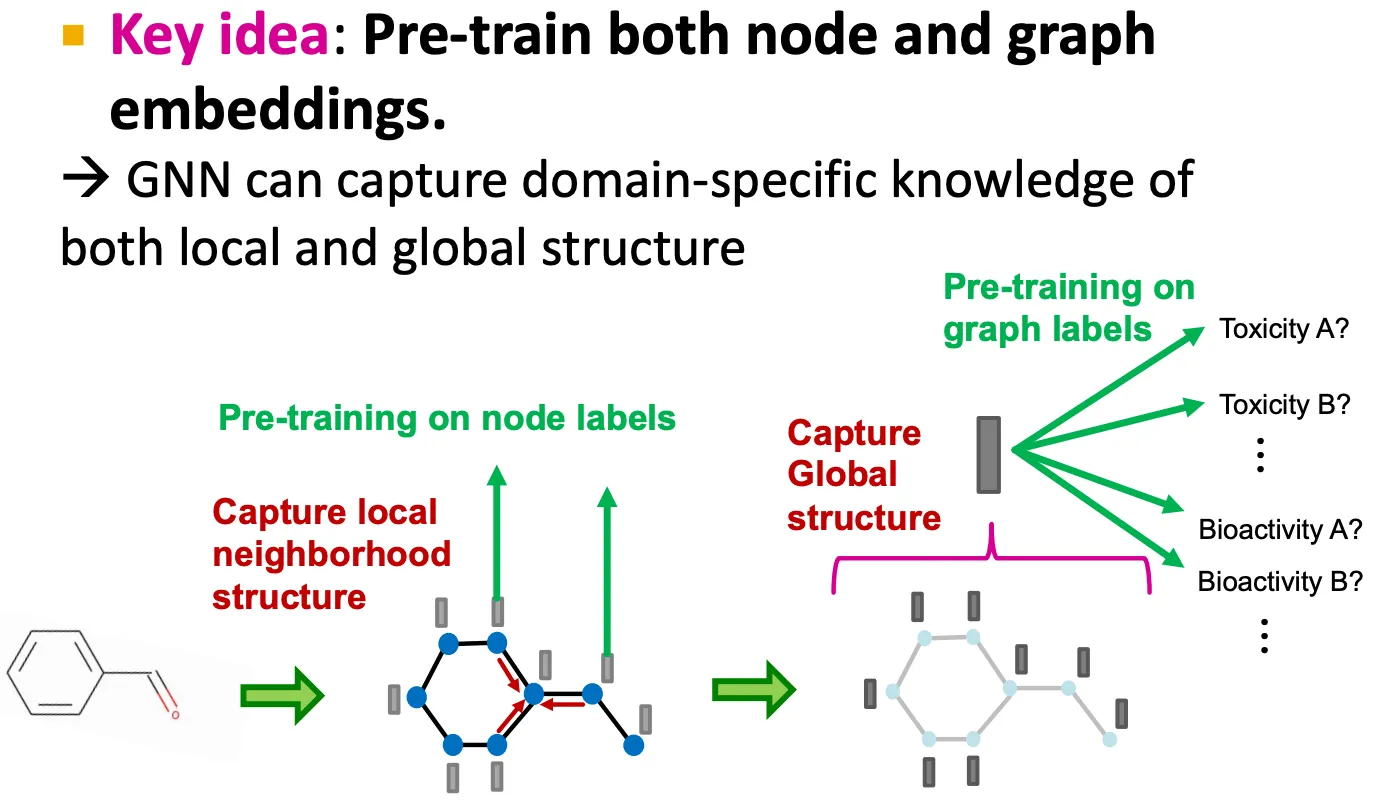
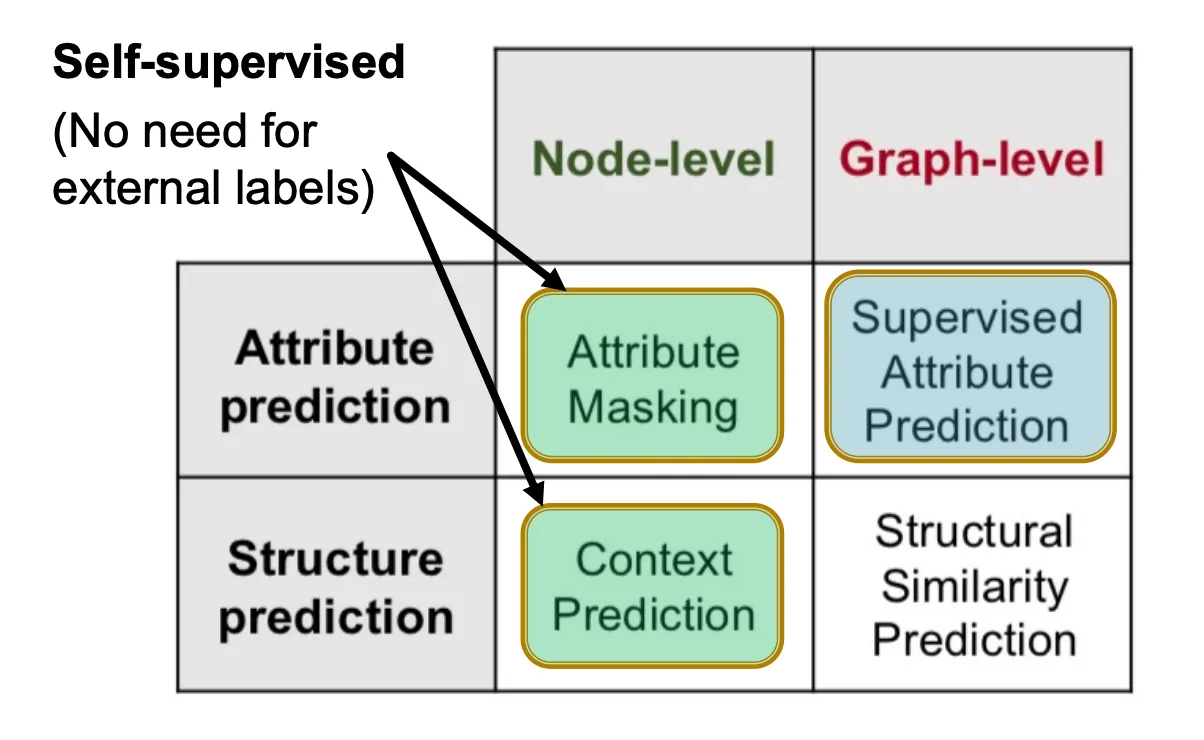
•
Attribute masking
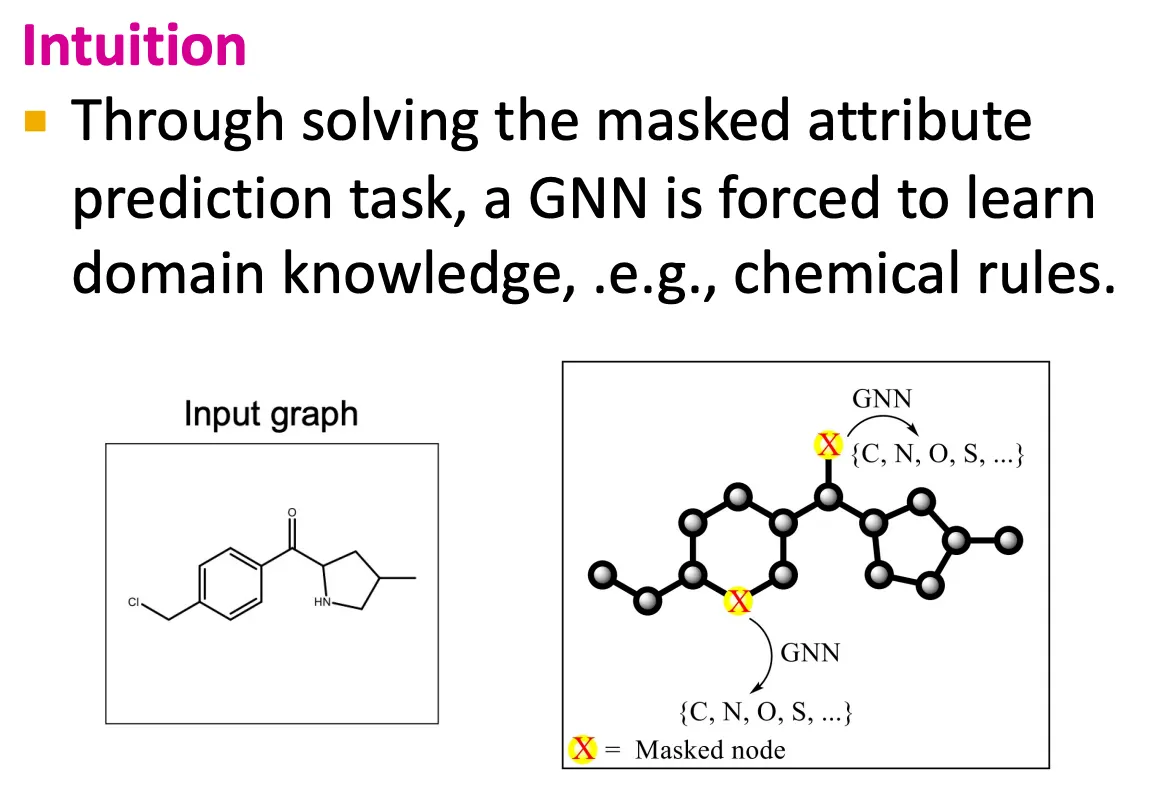
•
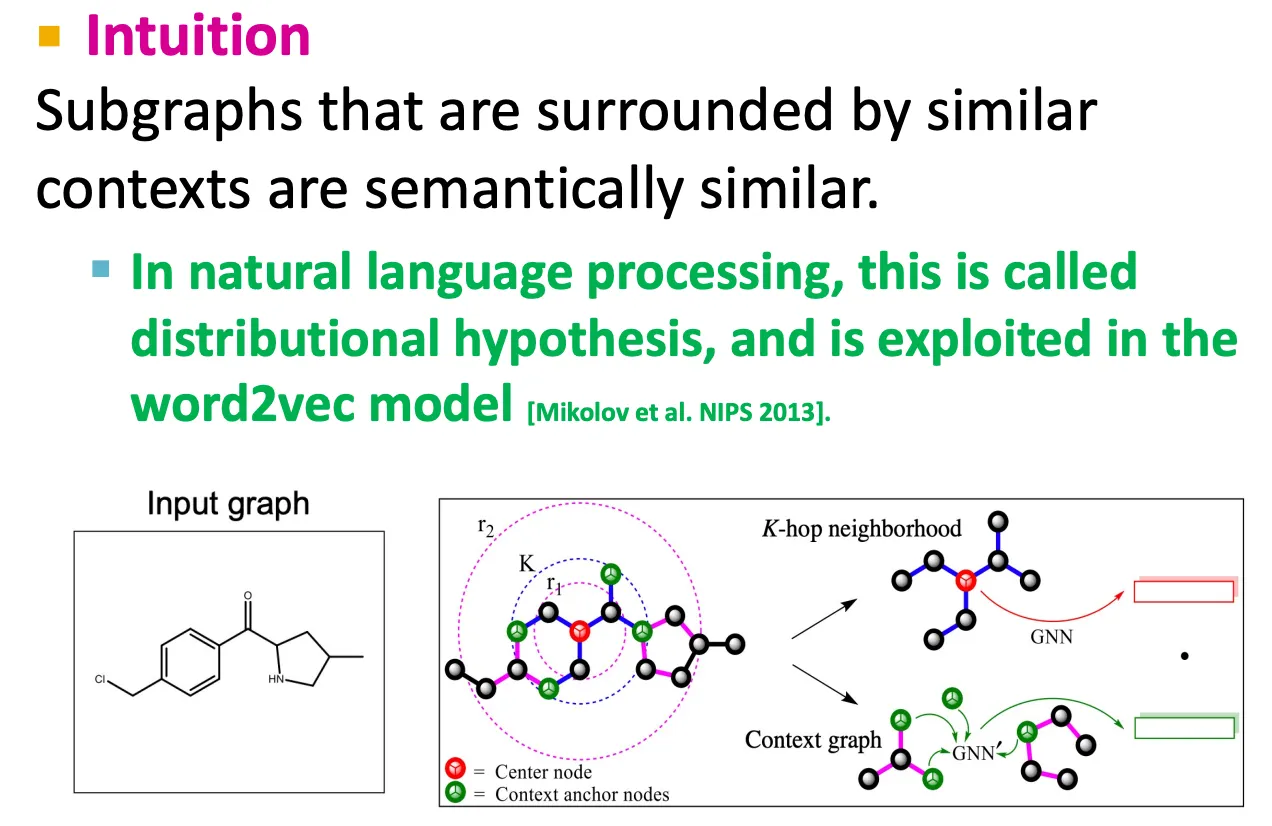
Context prediction
Results
Summary of Pretraining GNNs
