Abstract
Modeling sequential correlation of users’ historical interactions is essential in sequential recommendation. However, the majority of the approaches mainly focus on modeling the intra-sequence item correlation within each individual sequence but neglect the inter-sequence item correlation across different user interaction sequences. Though several studies have been aware of this issue, their method is either simple or implicit. To make better use of such information, we propose an inter-sequence enhanced framework for the Sequential Recommendation (ISSR). In ISSR, both inter-sequence and intra-sequence item correlation are considered. Firstly, we equip graph neural networks in the inter-sequence correlation encoder to capture the high-order item correlation from the user-item bipartite graph and the item-item graph. Then, based on the inter-sequence correlation encoder, we build GRU network and attention network in the intra-sequence correlation encoder to model the item sequential correlation within each individual sequence and temporal dynamics for predicting users’ preferences over candidate items. Additionally, we conduct extensive experiments on three real-world datasets. The experimental results demonstrate the superiority of ISSR over many state-of-the-art methods and the effectiveness of the inter-sequence correlation encoder.
Plain Text
복사
Introduction
•
주요 키워드
◦
Sequential recommendation (SR) : 순차적인 historical 정보 주어졌을 때, 다음 선호 아이템 예측
◦
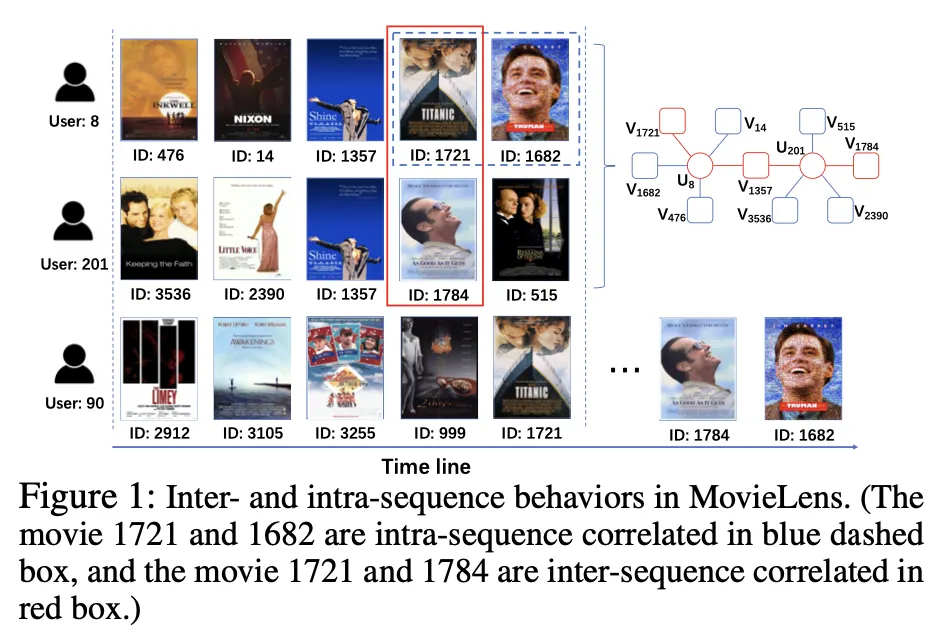
intra-sequence item correlation : 한 명의 유저 시퀀스에서 sequetial dependence를 가지는 두 아이템 (user 8 - 1721, 1682)
◦
inter-sequence item correlation : 두 명의 유저 시퀀스에서 공통 노드(아이템)를 가운데 두고 path를 가지는 두 아이템 (공통 노드 1357 - 1721, 1784)
◦
실제 user 90 의 경우 1721 시청 후 1784, 1682 시청 함 → intra-, inter- 모두 유익한 정보
•
Inter-Sequence enhanced framework for personalized Sequential Recommendation (ISSR) 제안
◦
기존 논문들은 intra-sequence item correlation 위주로 연구 → inter-, intra- 모두 고려
◦
사용자의 일반적인 취향 파악, 데이터 부족 문제 해결에 도움
•
inter-sequence correlation 파악하기 위해 GNN 사용
◦
Why GNN?
▪
high-order item correlation modeling
•
intra-sequence correlation 파악 위해 GRU, personalized attention network 사용
Method
•
Notation
◦
: set of users
◦
: set of items
ISSR
1.
inter-sequence item correlation encoder
2.
intra-sequence item correlation encoder
3.
prediction decoder
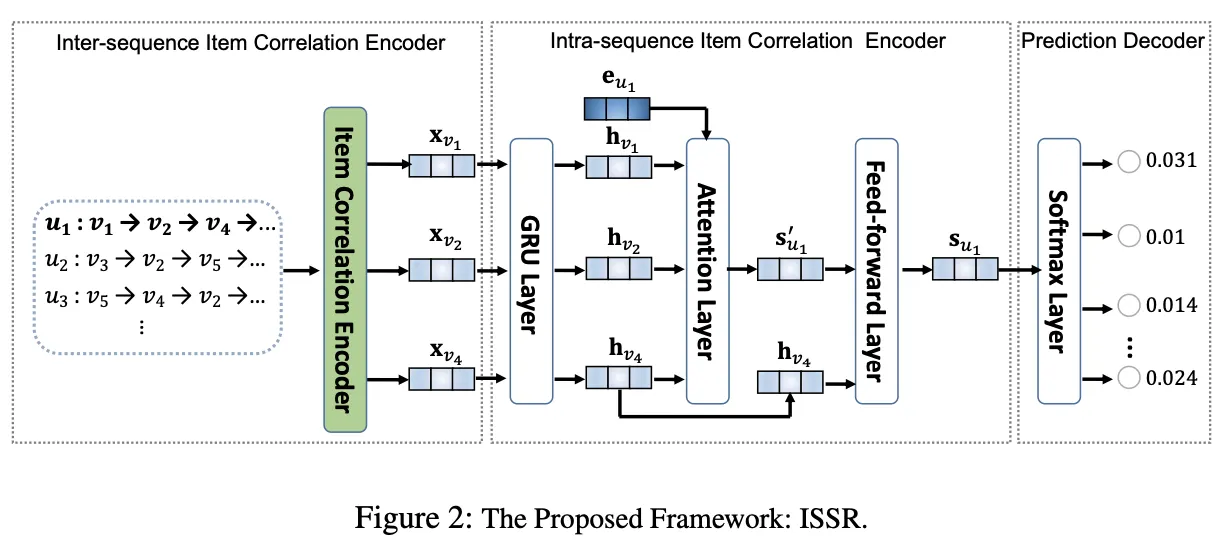
1. Inter-sequence Item Correlation Encoder
•
두 그래프 사용 : user-item bipartite graph / item-item co-occurrence graph
•
User-item bipartite 그래프
◦
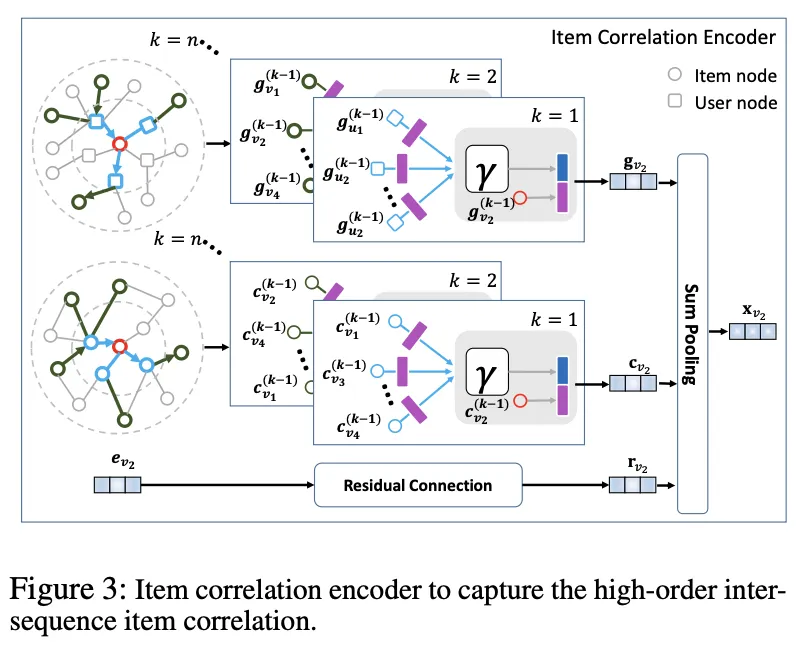
multiple GCN layers 사용해 -hop neighbors information을 aggregate
◦
layer-k 마다 다른 neural networks 사용
▪
user, item 노드들의 특징 본질적으로 다르기 때문
◦
Notation
▪
: initial embedding of item node
▪
: hidden representation of at layer- (그림의 보라색)
▪
: representation of the neighborgood of item node at layer-(-1) (그림의 파란색)
▪
: set of 1-hop neighbors of
▪
: weight matrix of item aggregator at layer-
▪
: bias of item aggregator at layer-
▪
: pooling function
▪
: activateion function
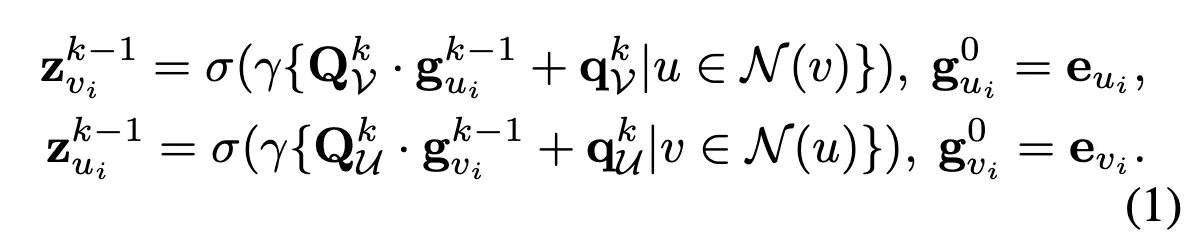
◦
: transformation weight matrix of item a layer-
◦
: bias
◦
: concatenation
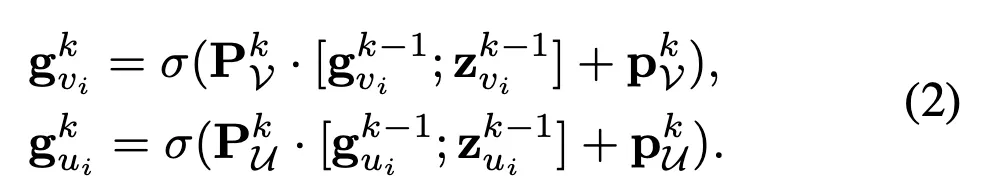
◦
captures the item correlation through multiple-hop neighbors in the user-item biparite graph
•
Item-Item co-occurrence graph
◦
user-item 그래프의 보완 역할 - item dependence의 빈도를 모델링
◦
node : item
◦
edge : 사용자의 sequence에서 두 아이템이 인접하면 연결 / 가중치는 두 항목이 인접해 발생한 횟수
◦
GCN와 GCN의 차이 : 1)노드의 타입이 하나, 2)weighted edge이기 때문에 이웃 샘플링 전략 다름
•
요약 : user-item, item-item 두 그래프를 통해 inter-sequence item correlation을 capture
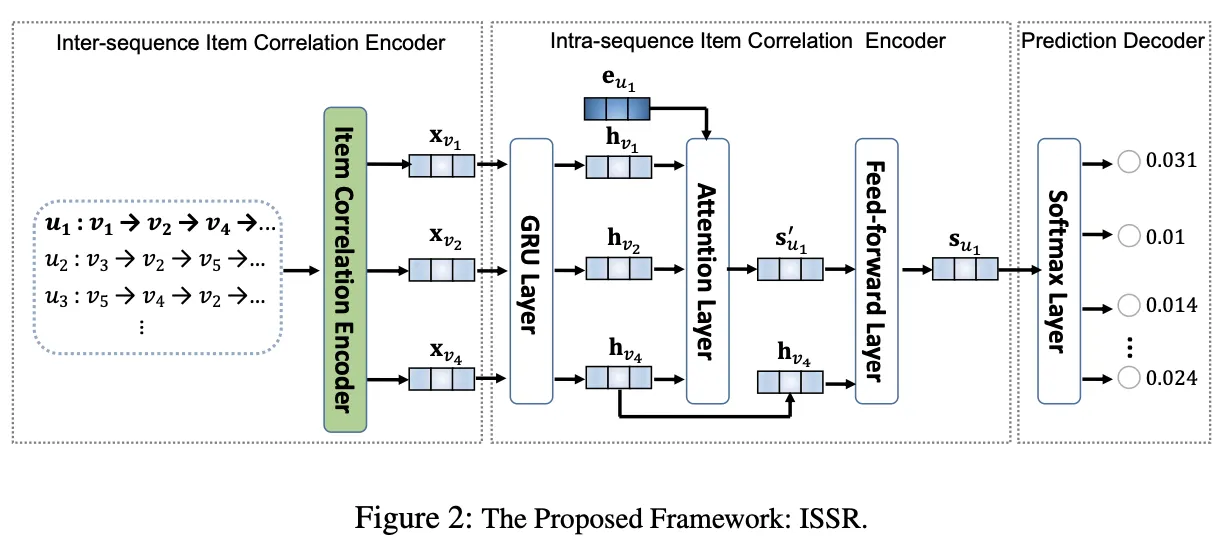
2. Intra-sequence Item Correlation Encoder
•
목표 : 앞에서 얻은 inter 정보 이용해 intra correlation 모델링
•
GRU layer : time step에 따른 user의 선호도 표현
•
Attention network : GRU 통해 얻은 user의 시간에 따른 선호도 이용해 user의 현재 선호도 generating
◦
유저의 현재 선택은 그동안 어떤 선택을 했는지에 따라 달라짐
◦
유저에 따라 temporal dynamics의 sensitivity 정도 다름
◦
peronalized attention netowrk 고안
◦
: embedding of the user → attention score 계산할 때 각 와 concat
◦
마지막 아이템은 유저의 최신 관심 가장 잘 반영 → 마지막 과 output concat
3. Prediction Decoder
•
유저의 최종 output ()과 각 아이템의 임베딩 를 내적하고 softmax 거쳐 prediction score 구함
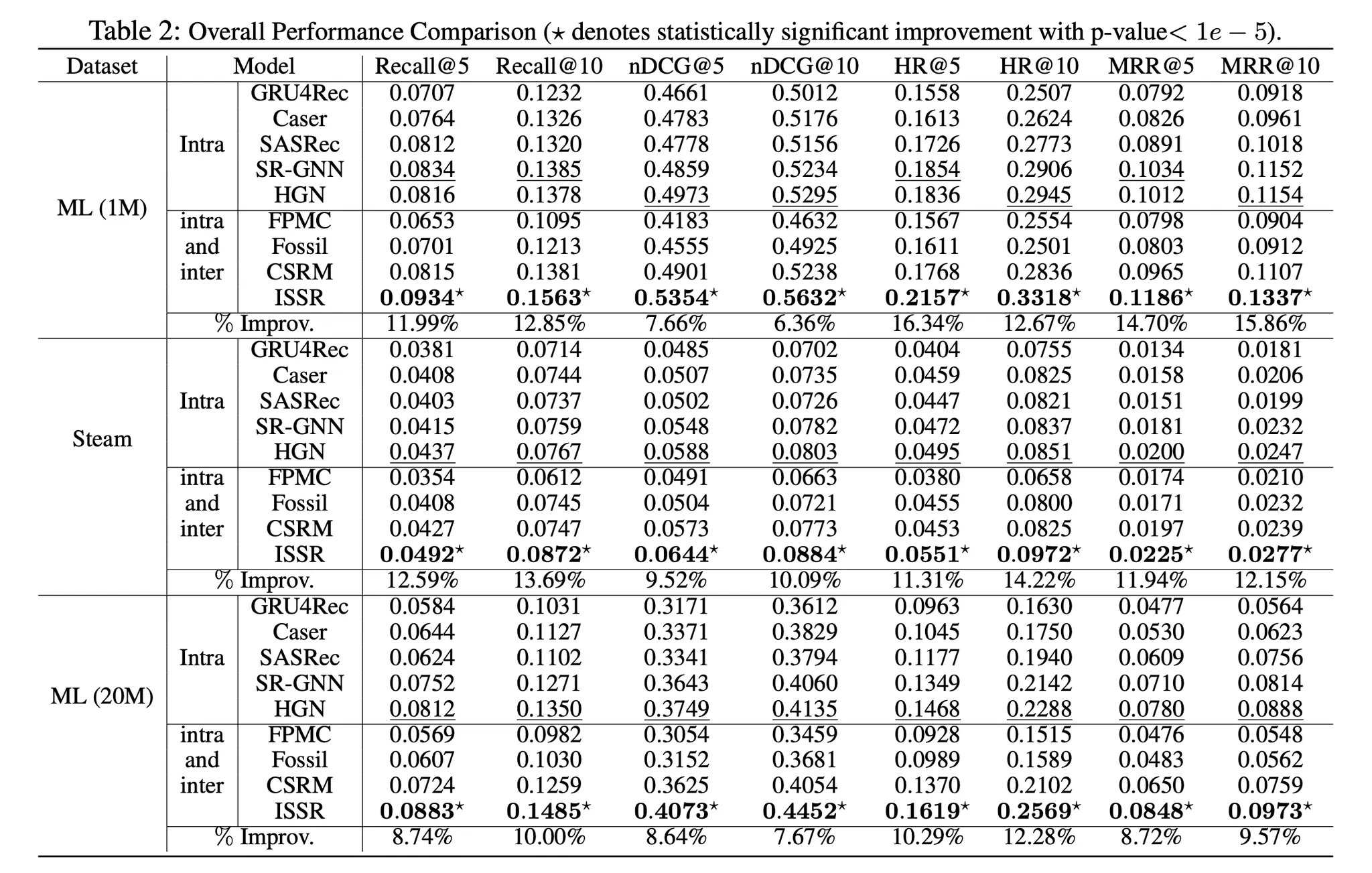
Experiments
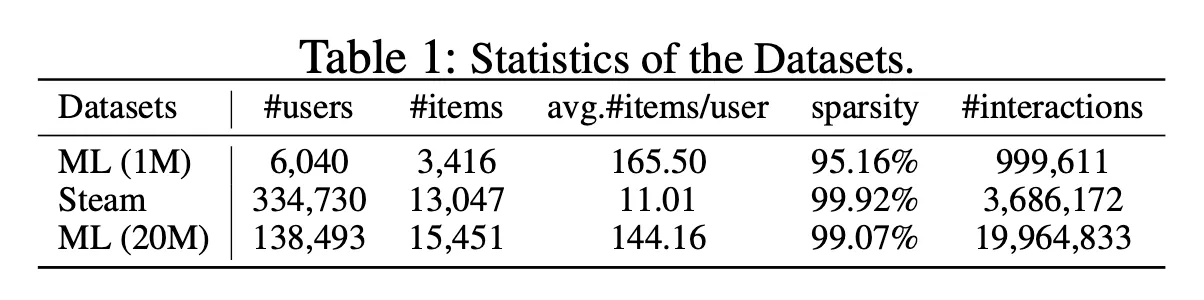
•
MovieLens(1M), Steam, MovieLens(20M)
•
training set : 유저 시퀀스의 첫번째 70%
•
val set : 그 다음 10%
•
test set : 마지막 20%
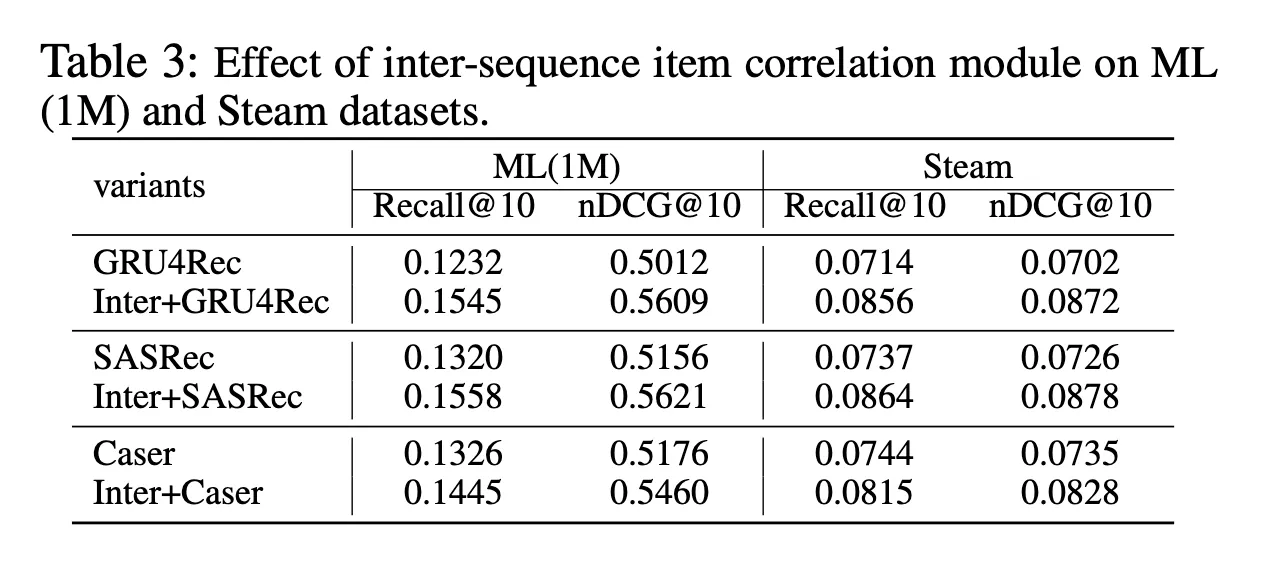
•
기존 다른 method에 inter 정보 사용했을 때 성능 좋아짐
•
ablation