

•
LightGCN 저자들이 작성한 논문
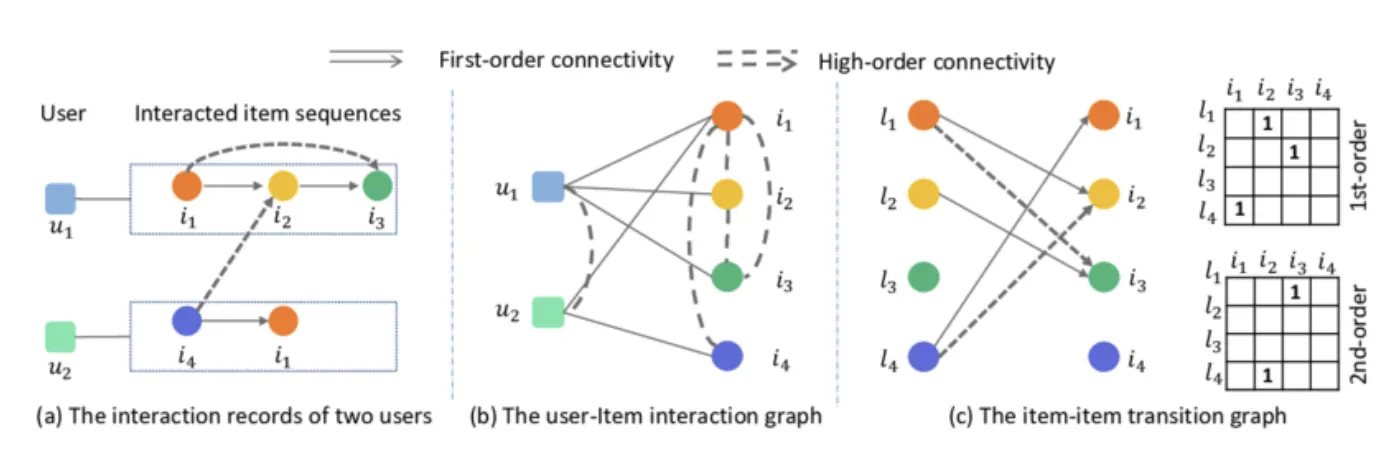
이해를 돕기 위한 그림 (논문 X)
Abstract
1.
기존 user-item graph for recommendation 의 문제점들 (LightGCN, PinSage)
•
high-degree node (short-head) 상품은 잘 추천되지만 low-degree (long-tail) 아이템의 경우 representation learning이 쉽지 않고 추천도 잘 되지 않는다.
•
neighbor hood aggregation을 진행하면 edge를 그대로 학습하기 때문에 노이즈에 취약하다는 단점이 있다.
2.
이 논문의 해결방법
•
self-supervised learning을 통해 accuracy와 robustness를 증가시켰다.
•
기존 supervised task 모델에 보조적으로 적용할 수 있는 장점이 있다.
3.
SGL (self-supervised graph learning) 방법?
•
node dropout, edge dropout, random walk를 통해 graph 구조를 바꾼다.
Introduction
기존 user-item collaborative filterning의 경우 matrix factorization에서 embedding vector를 쓰는 딥러닝 기반 방법, user의 interaction history를 추가하여 학습하는 방법, user-item graph를 사용하는 방법(GCN)으로 발전했다.
GCN-based recommendation의 문제점들
•
Sparse Supervision Signal
◦
학습해야하는 전체 interaction space에 비해 실제 interaction 데이터는 매우 sparse함
•
Skewed Data Distribution
◦
high-degree node에 편향되어 학습된다.
•
Noises in Interactions
◦
user가 click을 하고 마음에 안들어서 이탈해도, 좋은 interaction이라고 생각하여 학습을 하게 된다.
→ Self-supervised learning의 경우 NLP/CV 분야에서 많이 적용되고 있고, Recommedation System에 적용하게 되면 데이터가 없는 interaction space를 조금 더 학습할 수 있다.
→ data augmentation (node, edge dropout, random walk)을 통해 각 node들이 더 가능한 경우들을 학습한다. contrastive learning을 통해서는 이렇게 다양한 경우들을 학습한 node들이 다른 node들과 구분될 수 있도록 한다.
Preliminaries
Terminology
•
, : 각각 user, item set
•
= : where indicates that user u has adopted item i
•
= where and
GCN
GCN의 가장 핵심적인 작업은 각 Node에 대한 정보를 Node의 이웃정보들을 반영하여 update하는 것
•
◦
은 l-th layer에서의 node representation
◦
운 Item embedding vector
•
l번째 layer의 user node vector :
•
최종 node vector :
Supervised Learning Loss
어떤 user가 어떤 item을 선호할지는 inner product로 나타낼 수 있다.
•
objective function으로는 Bayesian Personalized Ranking Loss 을 사용한다.
•
•
i는 user-item간 interaction이 있는 observed interaction이고 j의 경우 unobserved interaction이다.
•
를 보다 커지게 만드는 것이 목적
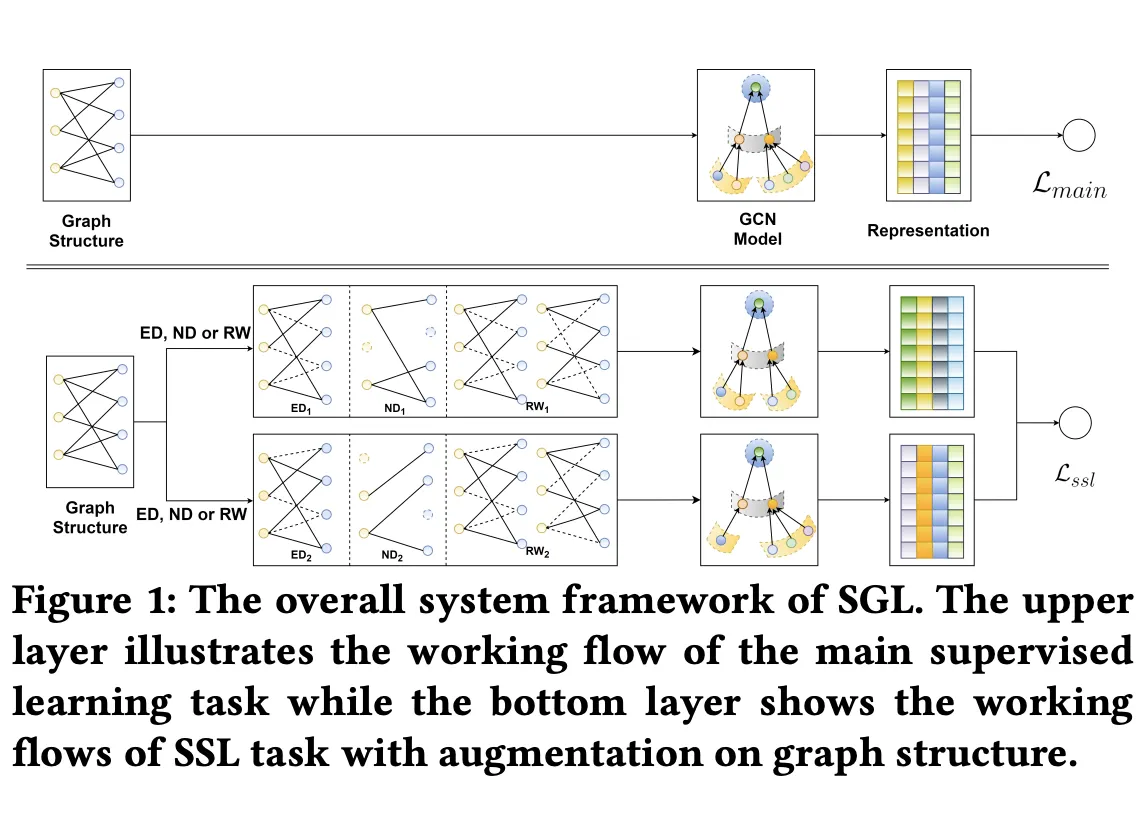
Methodology
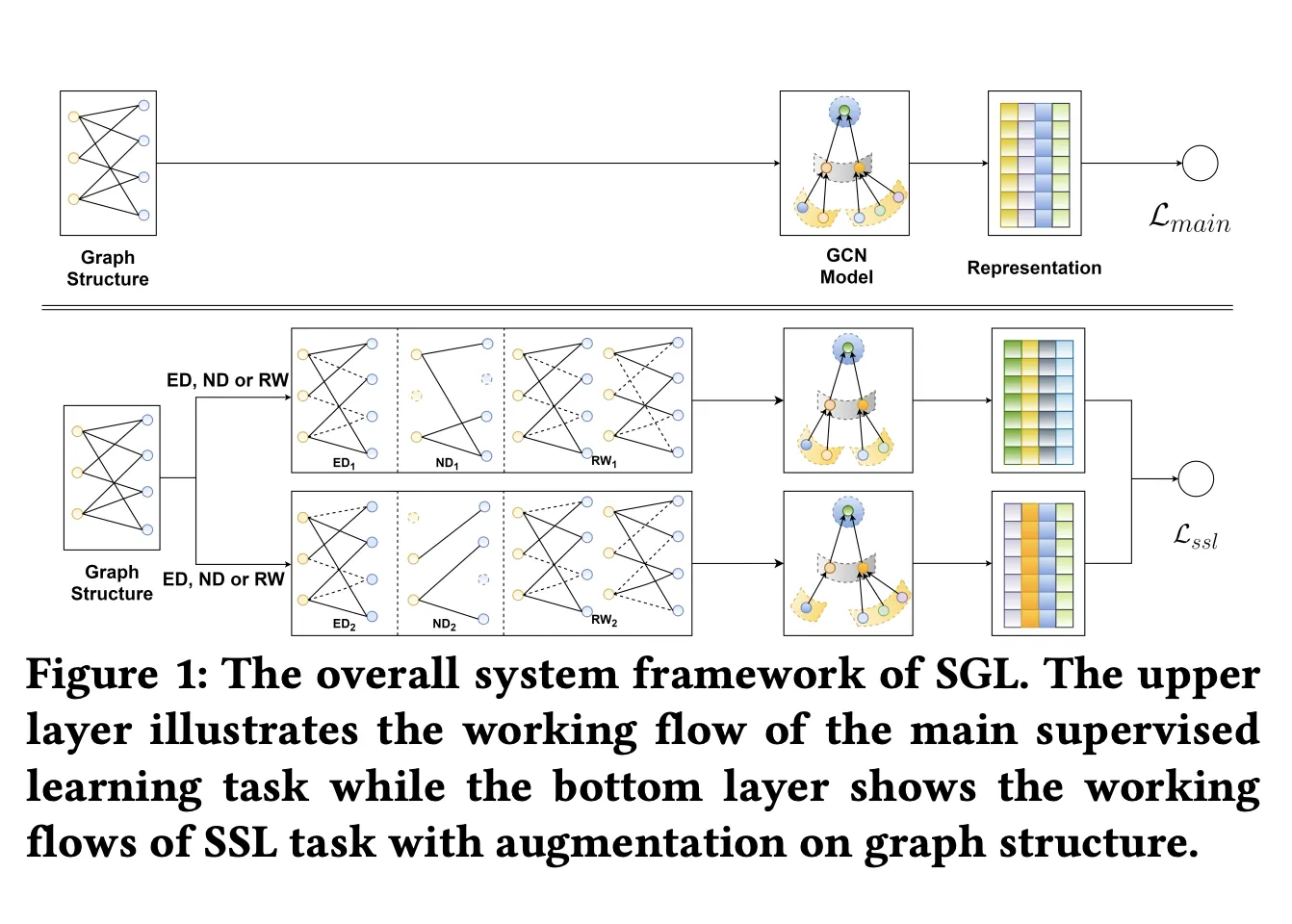
→ 기존 GCN 방법으로 node representation을 학습하고, data augmentation을 통해 multiple representation view를 만들어내서 self-supervised learning을 진행한다.
Data Augmentation
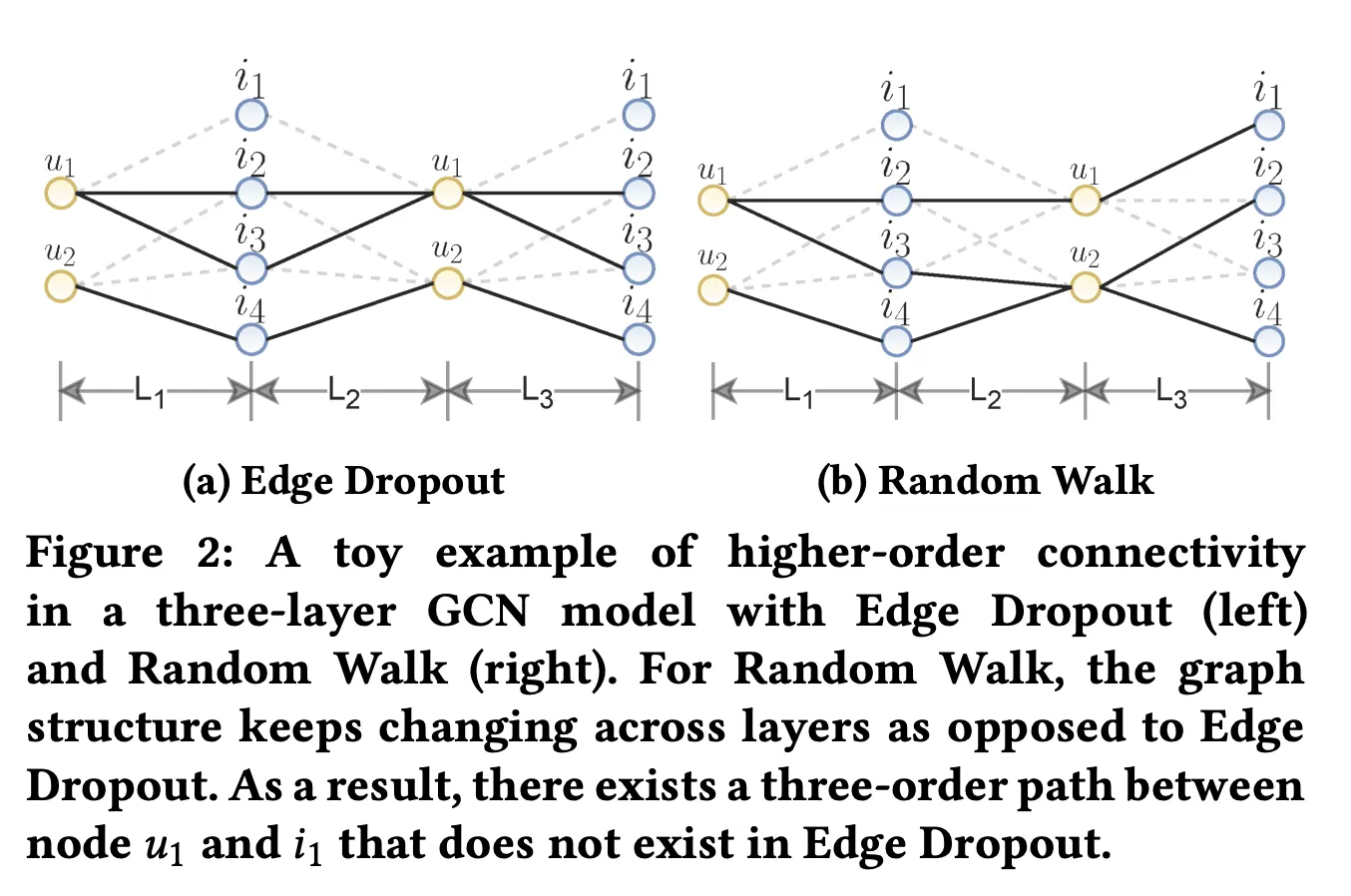
Augmentation은 epoch마다 새롭게 진행한다. Augmentation을 통해 독립적인 두개의 graph를 만든 다음, 최종적으로 나오는 두 representation vector들을 비교한다.
1.
Node Dropout
•
일정 확률로 특정 node를 graph에서 제외한다. (user node item node 상관 X)
2.
Edge Dropout
•
일정 확률로 edge를 graph를 제외한다.
3.
Random Walk
•
매 layer마다 random하게 edge를 선택한다.
•
다른 augmentation은 graph의 구조가 한 epoch동안 유지되지만, random walk의 경우는 아니다.
Contrastive Learning
두개의 graph의 최종 representation vector에서 같은 node의 경우 positive pair라 생각하고, 다른 node의 경우 negative pair로 생각한다.
•
◦
: hyperparameter
◦
: 두 vector간 similarity 구하는 함수
◦
의 값은 높이고, 의 값은 낮춘다.
•
item에 대해서도 똑같이 적용
Multi-task Training
•
→ 동시에 ssl까지 학습하는 multi-task learning을 진행하였는데, 먼저 ssl로 pretraining하고 main task를 진행하는 방식도 있었음 (뒤에 결과에서 소개)
Theoretical Analyses of SGL
ssl이 recommendation task에 도움이 되는지 확인하기 위해 ssl loss에 대한 user representation의 gradient를 구했다.
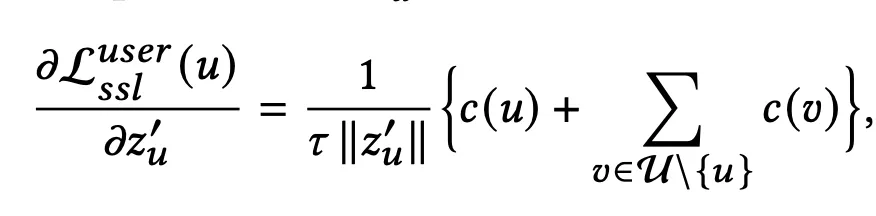
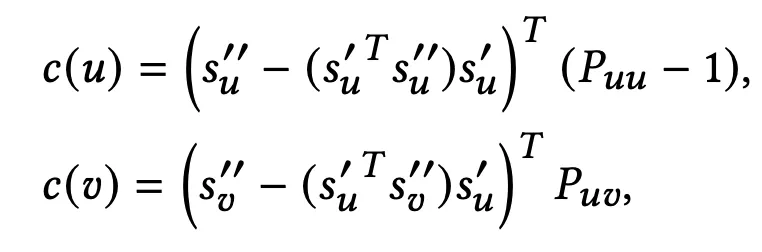
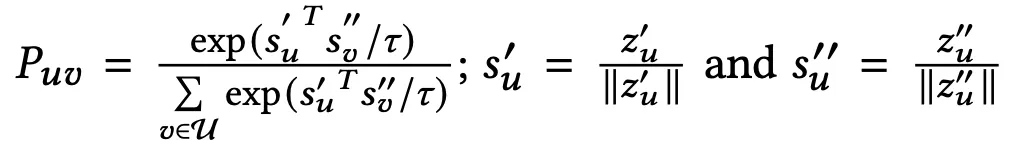
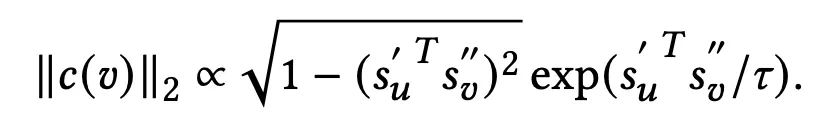
→ gradient는 로 나타낼 수 있는데, 의 square는 마지막 식에 비례하는 값이다.
→ 이 식을 또 간단하게 표현하면 다음과 같다.
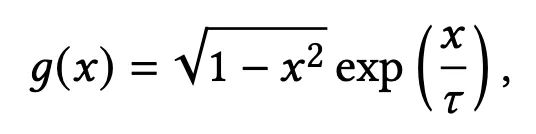
•
x는 로 두 벡터간 similarity를 의미한다. 이때 unit vector이므로 -1~1의 값을 가짐.
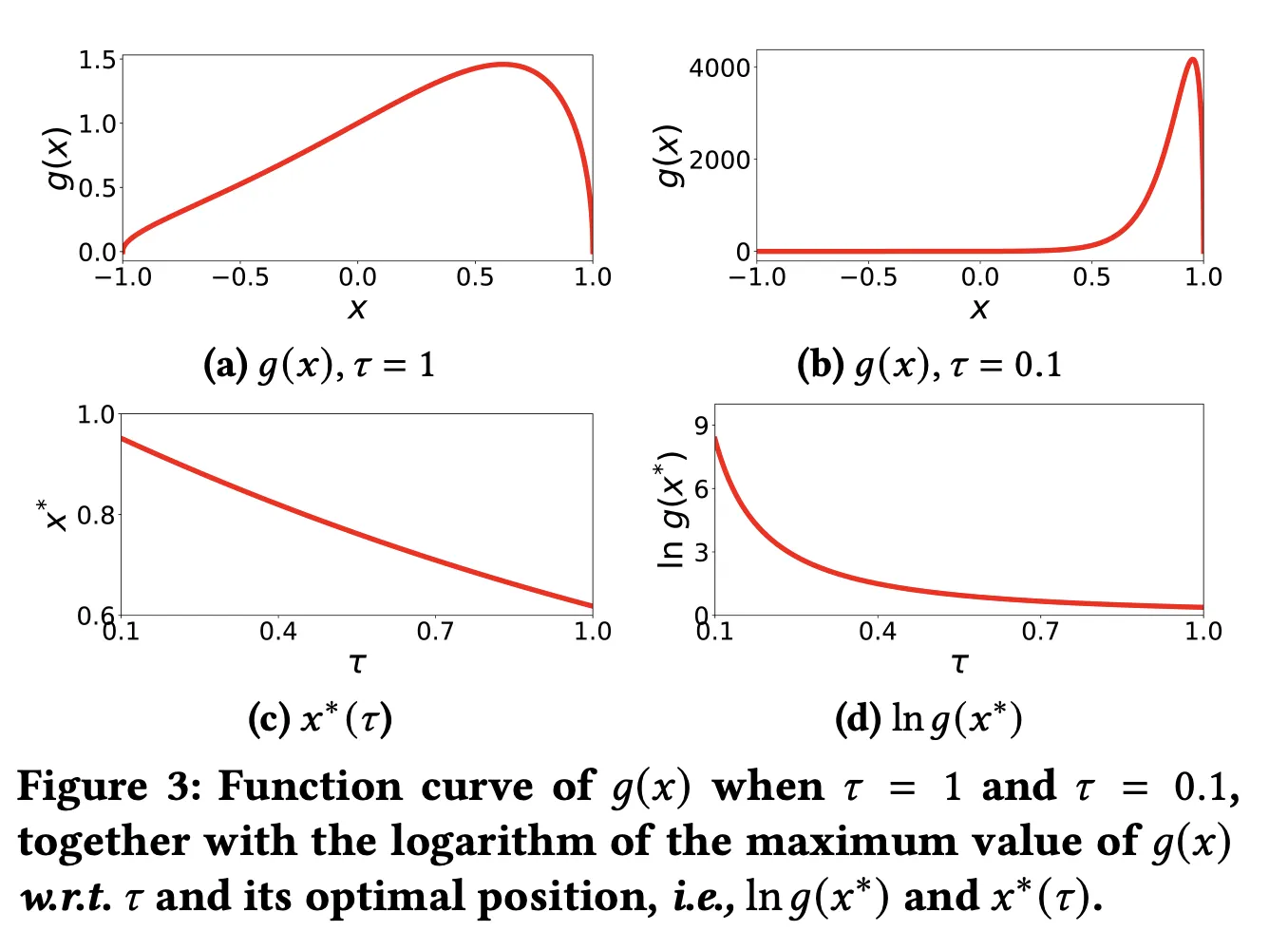
•
g(x) 값으로 그래프를 그렸는데, x의 값에 따른 g(x)의 분포가 좋다.
•
x가 0에서 1의 값인 경우 와 가 비슷한 경우를 의미한다. 즉, 가 hard negative 이며 잘 구분되지 않는 경우이다.
•
x가 -1~0 범위보다 0~1 범위에서 g(x)값이 훨씬 크다. (특히 hyperparameter 조정한 (b)에서)
→ hard-negative 인 node에 대해서 gradient를 더 많이가함으로써 잘 구별되지 않는 node들을 잘 구별할 수 있도록 학습한다.
Complexity Analyses of SGL
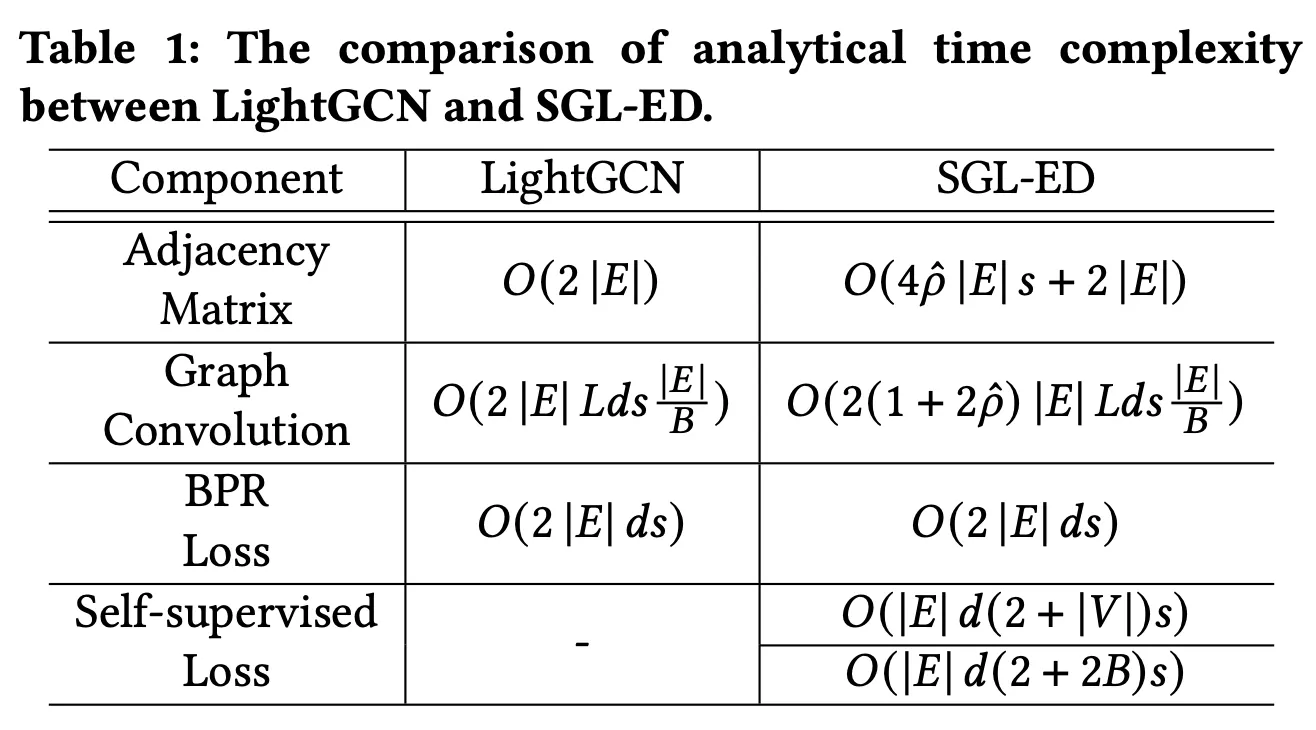
•
LightGCN과 time complextity를 비교하였다.
•
time complexity가 증가하긴하지만, 대략 3.7배로 나쁘진 않다고 주장
Experiments
•
Yelp2018, Amazion-Book, Alibaba-iFashion 데이터셋을 사용하였음
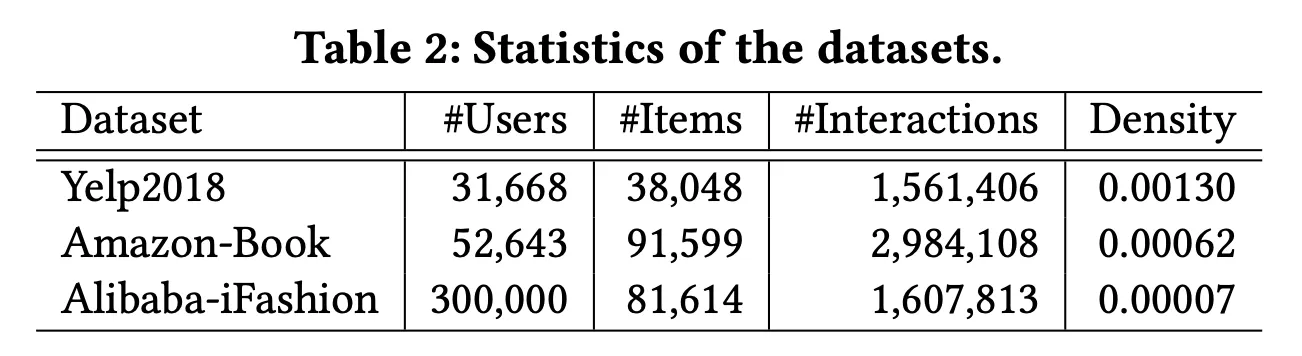
사용한 Metric
→ long-tail 에 대한 추천을 확인하기 위해 전체 item을 인기순으로 10개의 group으로 분류하였음
•
: top-20개 추천
1.
SGL 방식에서 각각의 방법별 성능 비교
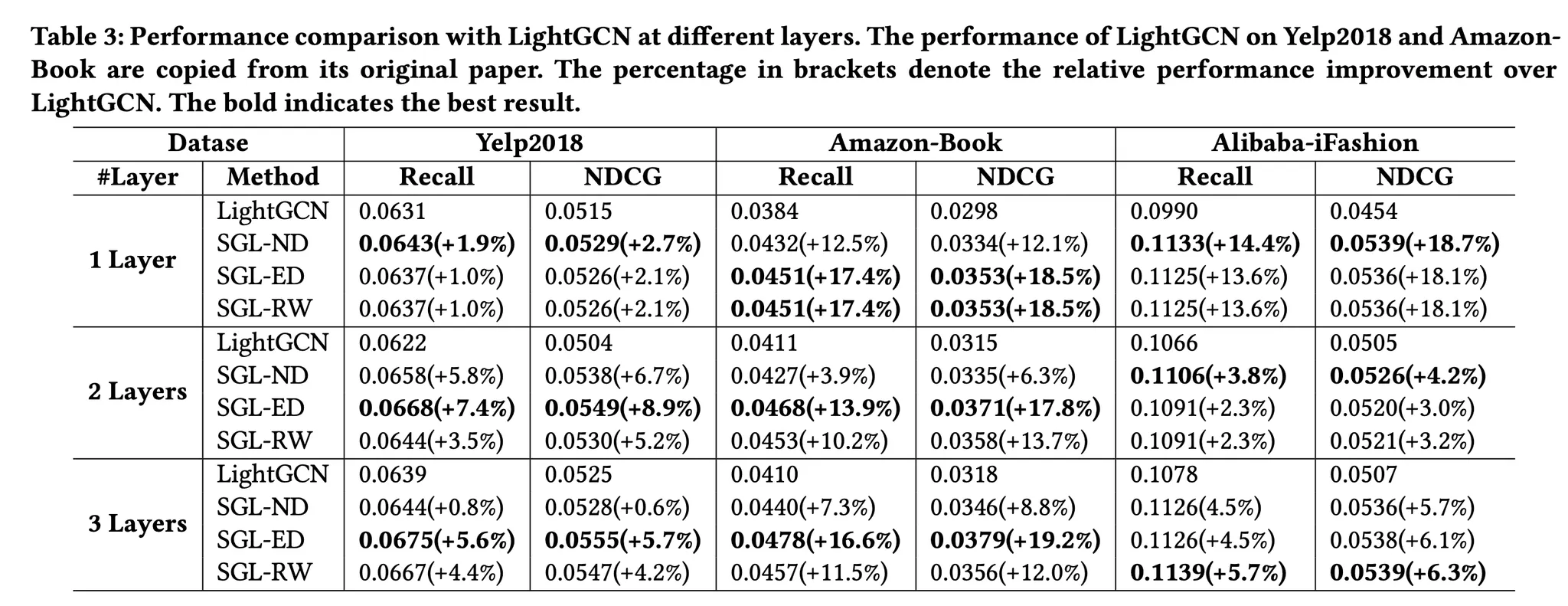
•
layer가 많아질수록 성능이 높아지며 SGL-ED가 다른 방법에 비해 성능이 가장 좋다.
2.
다른 SOTA 모델과 전체 성능 비교
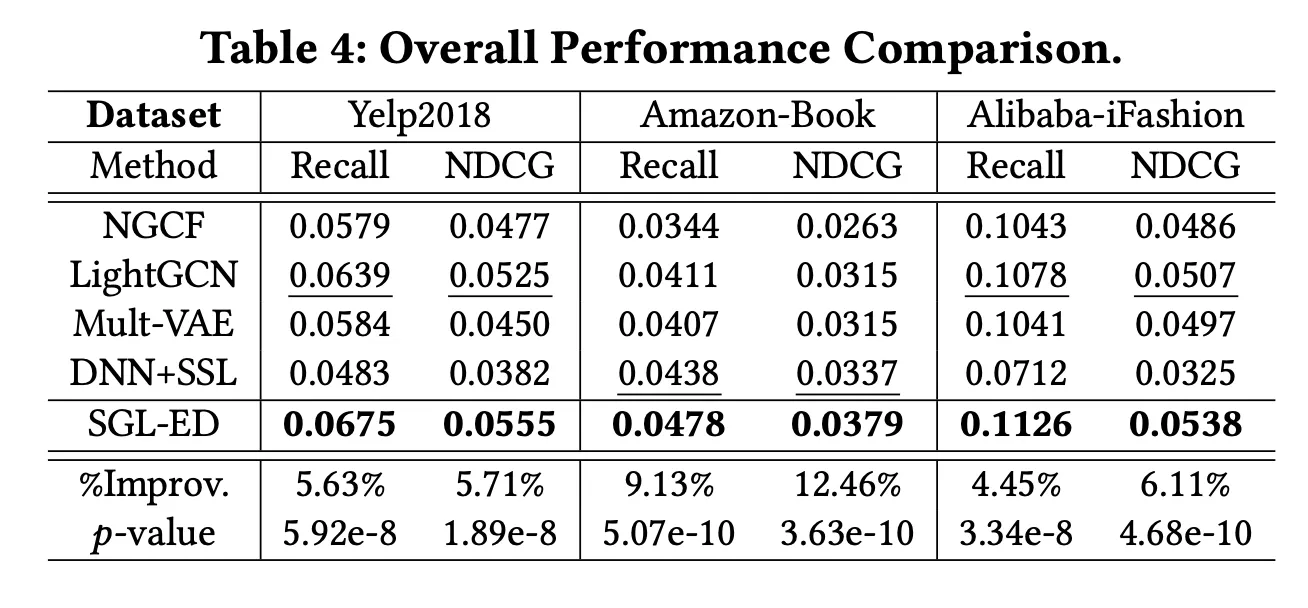
3.
LightGCN과 group 별 비교
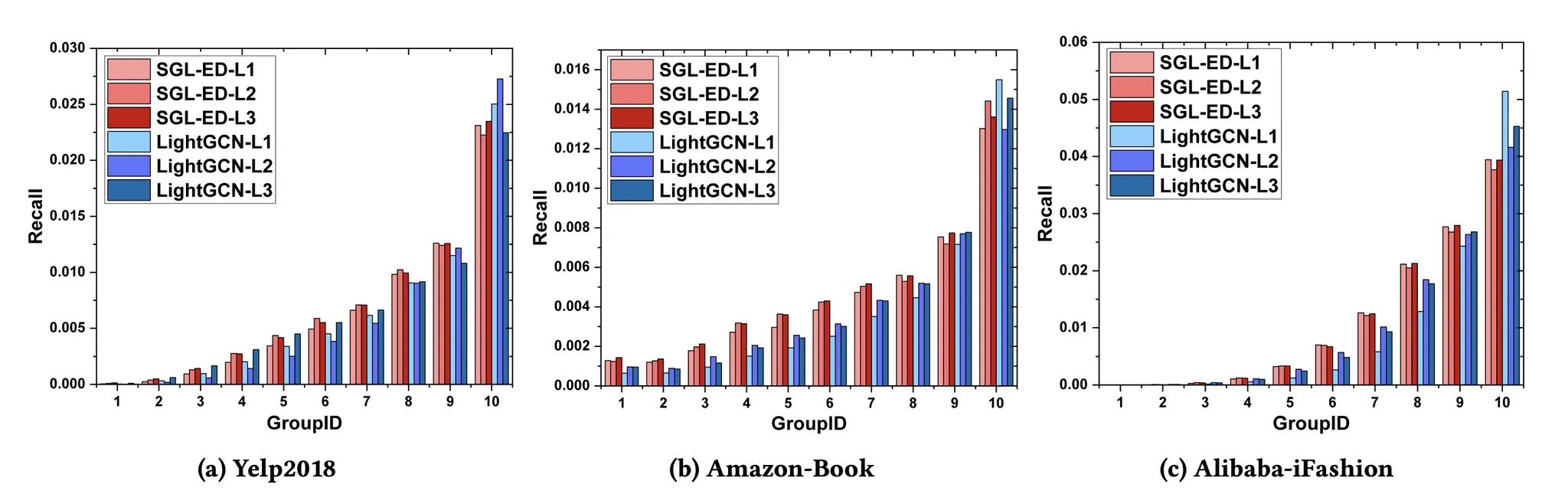
•
group id가 낮은 경우 (long-tail) SGL-ED 방식이 성능이 훨씬 좋다.
•
group id가 높은 경우 LightGCN의 성능이 더 좋은 편이다.
4.
수렴 속도
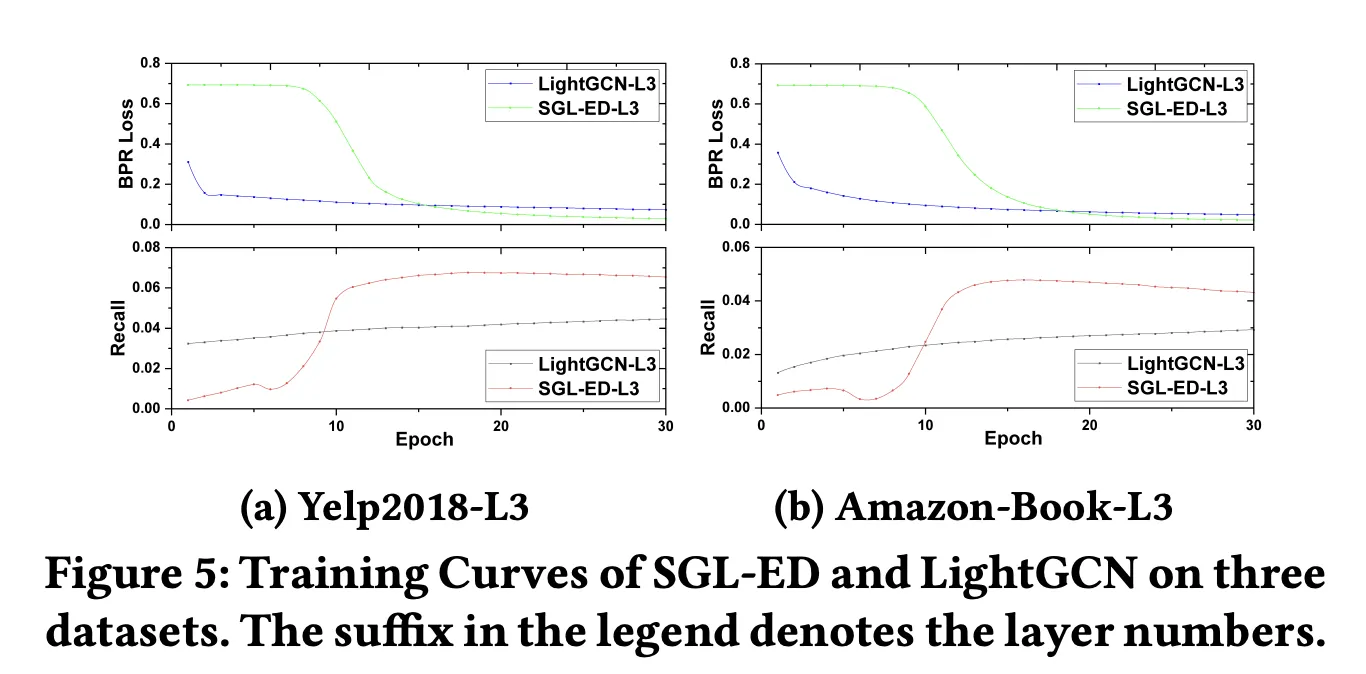
•
SGL-ED가 더 천천히 수렴하지만, 더 낮은 값까지 수렴한다.
5.
Noise에 대한 robustness
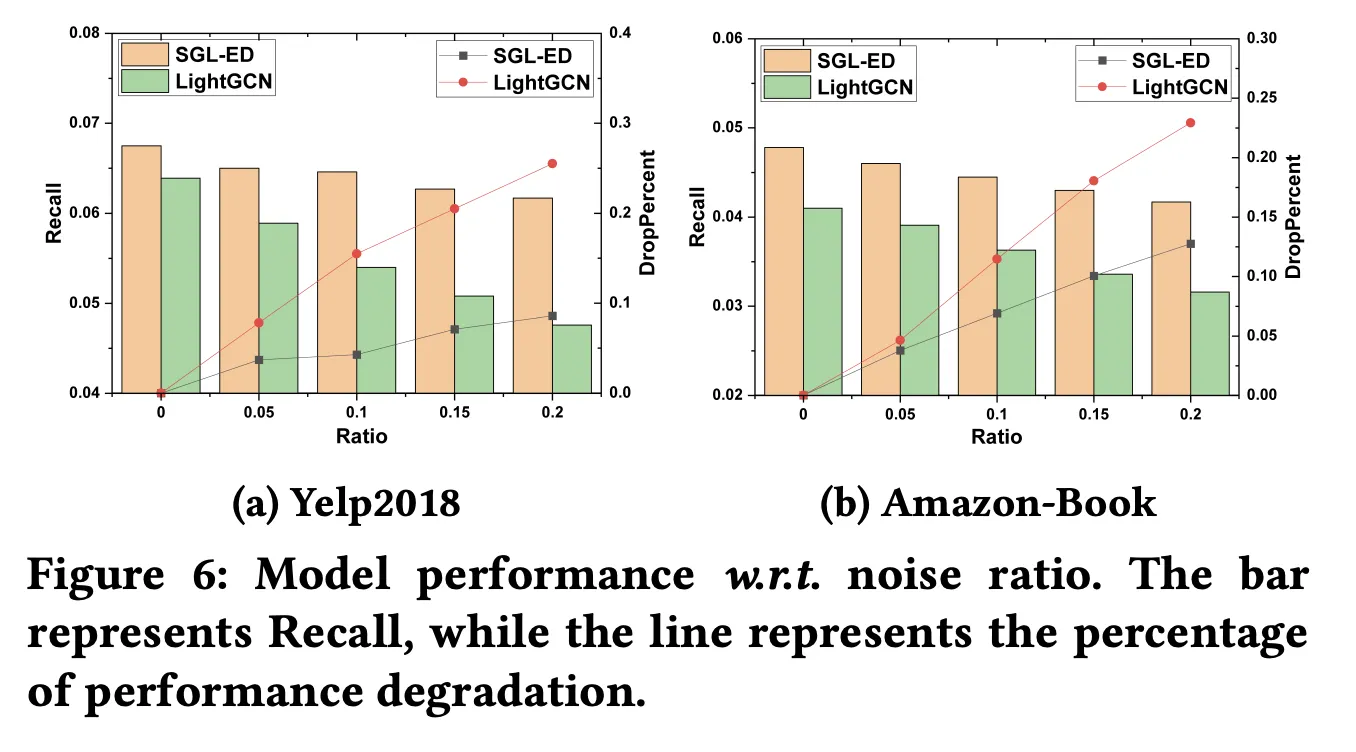
•
하단의 ratio가 noise (가짜 user-item interaction)을 추가한 비율
•
왼쪽의 Recall과 bar는 noise를 추가할 때 측정한 성능
•
오른쪽의 droppercent과 line은 ratio=0 대비 떨어진 성능
→ SGL-ED가 LightGCN에 비해 noise에 강한 것을 볼 수 있다.
6.
Pretraining 방법과의 비교
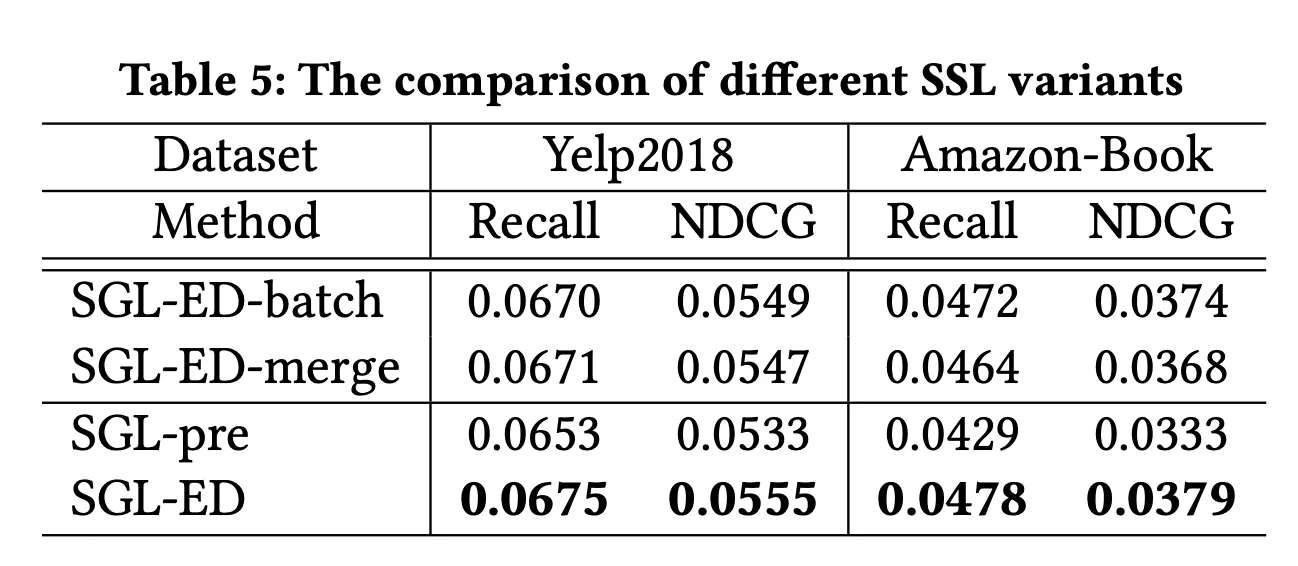
•
pretraining으로 SSL을 먼저 진행하고 main task를 진행하는 것보다 multi task로 학습하는 것이 훨씬 성능이 좋다.
•
SGL-ED-batch와 SGL-ED-merge의 경우 negative sample을 뽑아내는 방식에 대한 실험이다.
◦
SGL-ED-batch의 경우 mini-batch 단위에서 negative sample을 뽑아낸다.
◦
SGL-ED-merge의 경우 마찬가지로 mini-batch에서 negative sample을 뽑아내는데, node type을 구분하지 않음 (?)
→ mini-batch 단위가 아니라 전체 user-item graph에 대해서 interaction이 없는 negative sample을 뽑아내는 SGL-ED가 성능이 가장 좋다.
Conclusion And Future Work
•
더 좋은 data augmentation 방법을 만들 예정
•
Self-supervised learning graph를 recommendation system에 적용한 첫번째 사례
Abstract
Representation learning on user-item graph for recommendation has evolved from using single ID or interaction history to exploiting higher-order neighbors. This leads to the success of graph convolution networks (GCNs) for recommendation such as PinSage and LightGCN. Despite effectiveness, we argue that they suffer from two limitations: (1) high-degree nodes exert larger impact on the representation learning, deteriorating the recommendations of low-degree (long-tail) items; and (2) representations are vulnerable to noisy interactions, as the neighborhood aggregation scheme further enlarges the impact of observed edges.
In this work, we explore self-supervised learning on user item graph, so as to improve the accuracy and robustness of GCNs for recommendation. The idea is to supplement the classical supervised task of recommendation with an auxiliary self supervised task, which reinforces node representation learning via self-discrimination. Specifically, we generate multiple views of a node, maximizing the agreement between different views of the same node compared to that of other nodes. We devise three operators to generate the views — node dropout, edge dropout, and random walk — that change the graph structure in different manners. We term this new learning paradigm as Self-supervised Graph Learning (SGL), implementing it on the state-of-the-art model LightGCN. Through theoretical analyses, we find that SGL has the ability of automatically mining hard negatives. Empirical studies on three benchmark datasets demonstrate the effectiveness of SGL, which improves the recommendation accuracy, especially on long-tail items, and the robustness against interaction noises. Our implementations are available at https://github.com/wujcan/SGL.
요약
1.
GCN 모델들이 추천에 효과 적이었다. 일례로 PinSage, LightGCN 등이 있다. 하지만 이러한 모델의 경우 인기 상품은 잘 추천되지만 long-tail 아이템의 경우 추천이 잘 되지 않는다. 또한 노이즈에 취약하다는 단점이 있다.
2.
기존 graph 기반 추천 task에다가 self supervised task를 추가한 Self-supervised Graph Learning을 만들었다.
3.
Self discrimination task를 진행하는데, 그래프에서 node dropout, edge dropout, random walk 등을 진행하여 그래프 구조를 바꾼다음 representation vector를 구별하는 task이다.
4.
long-tail을 잘 추천하고 interaction 노이즈에 robust한 모델을 만들 수 있었다.
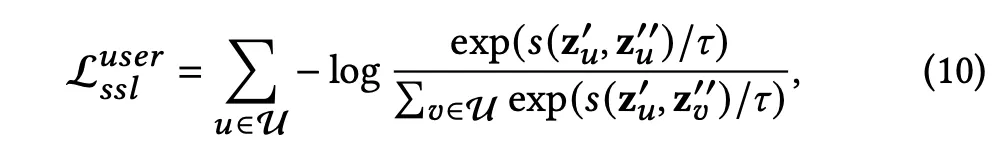
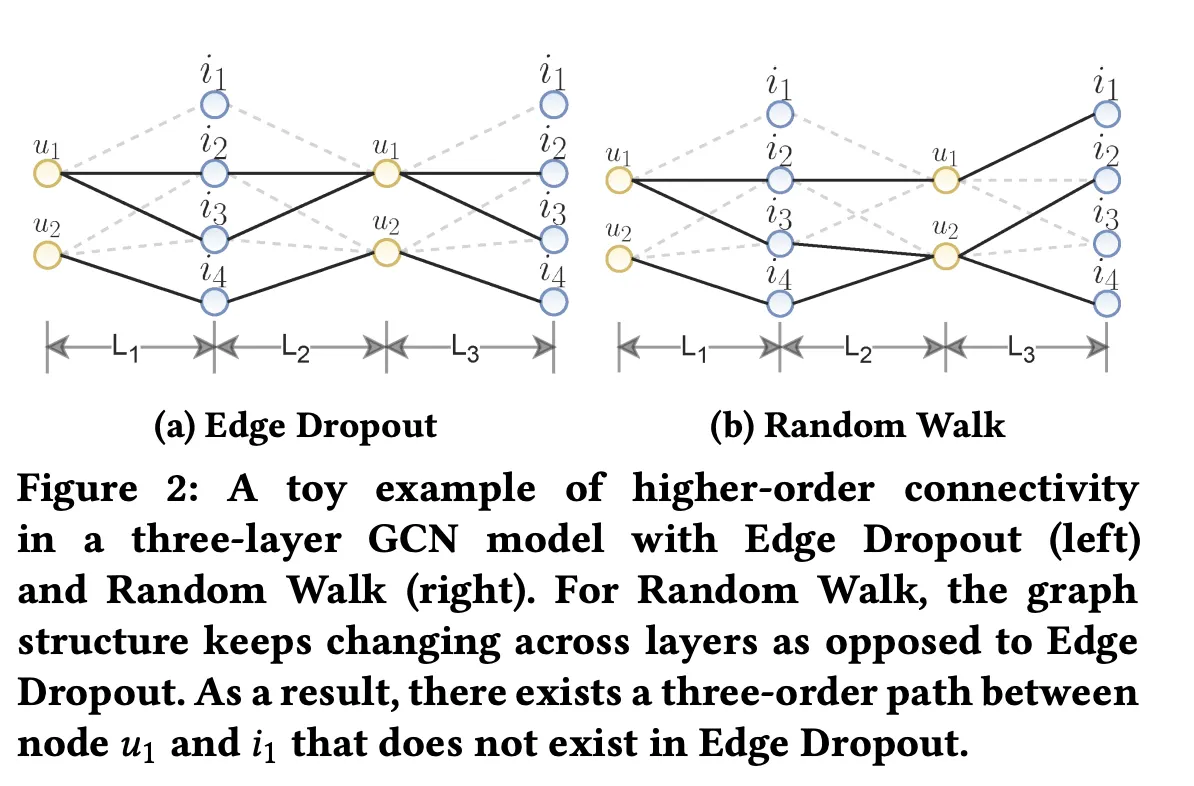
•
Edge dropout, random walk하는 방법
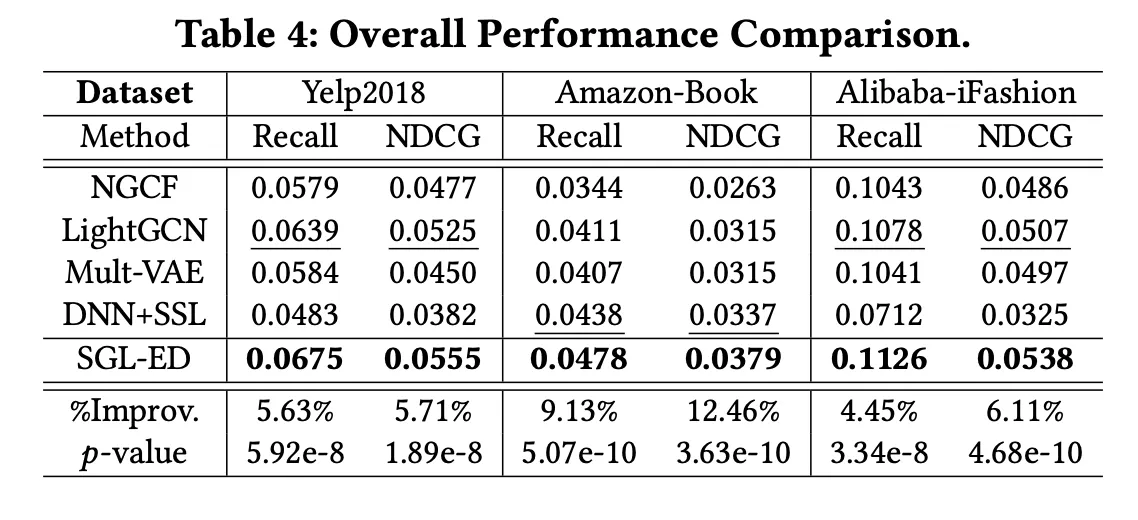
•
성능