
원문: Self-attention with relative position representations
Motivation
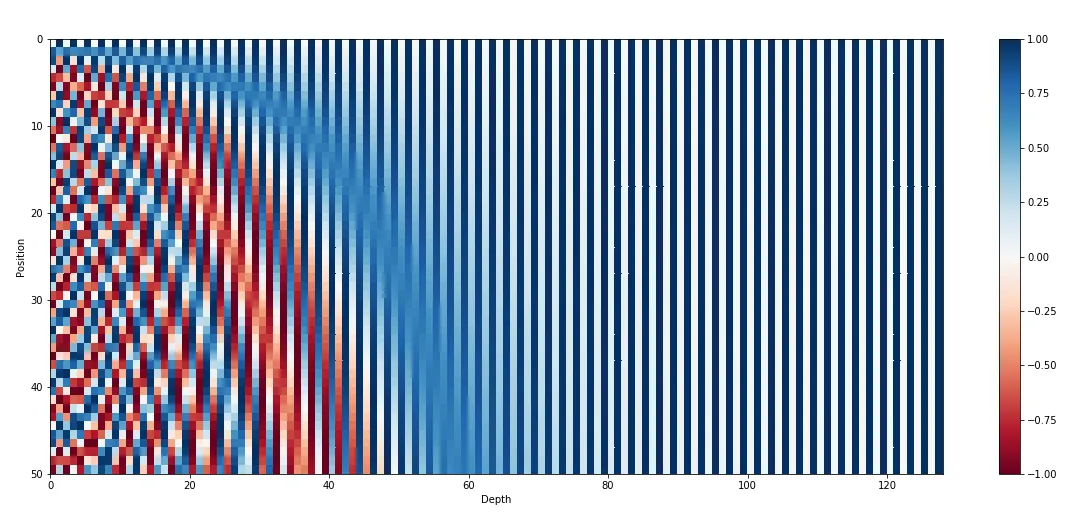
Vanilla Transformer (Attention is All You Need)는 위치 정보를 encoding 하기 위해 absolute position을 encoding하는 positional encoding (PE)을 사용한다.
참고: Absolute PE
하지만 absolute position 보다 relative position이 중요한 경우 (graph 구조 등)에는 어떤 PE를 사용해야 할까?
저자들은 self-attention 도중 learnable parameter로써의 PE를 제안한다.
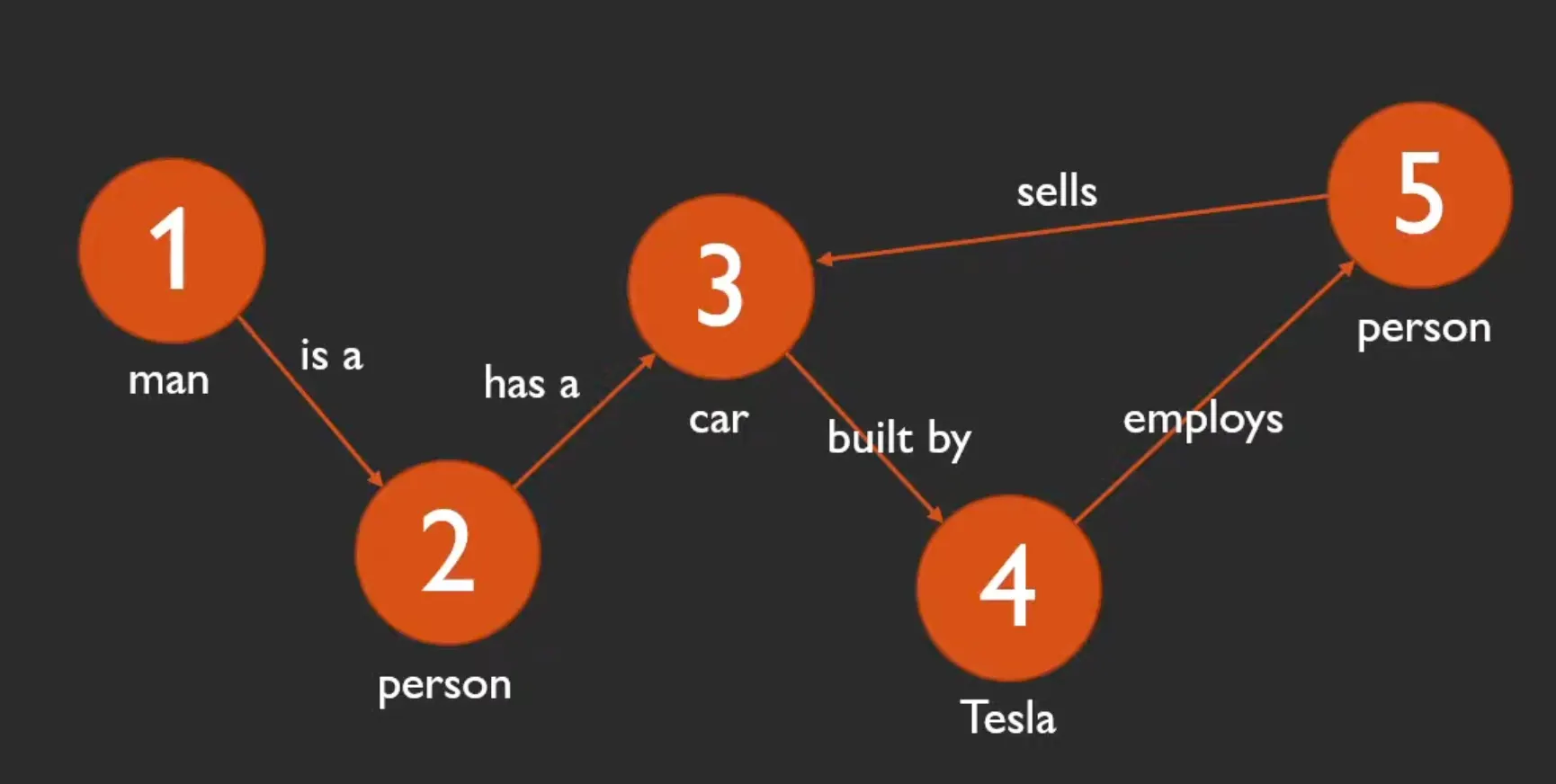
Graphical Understanding
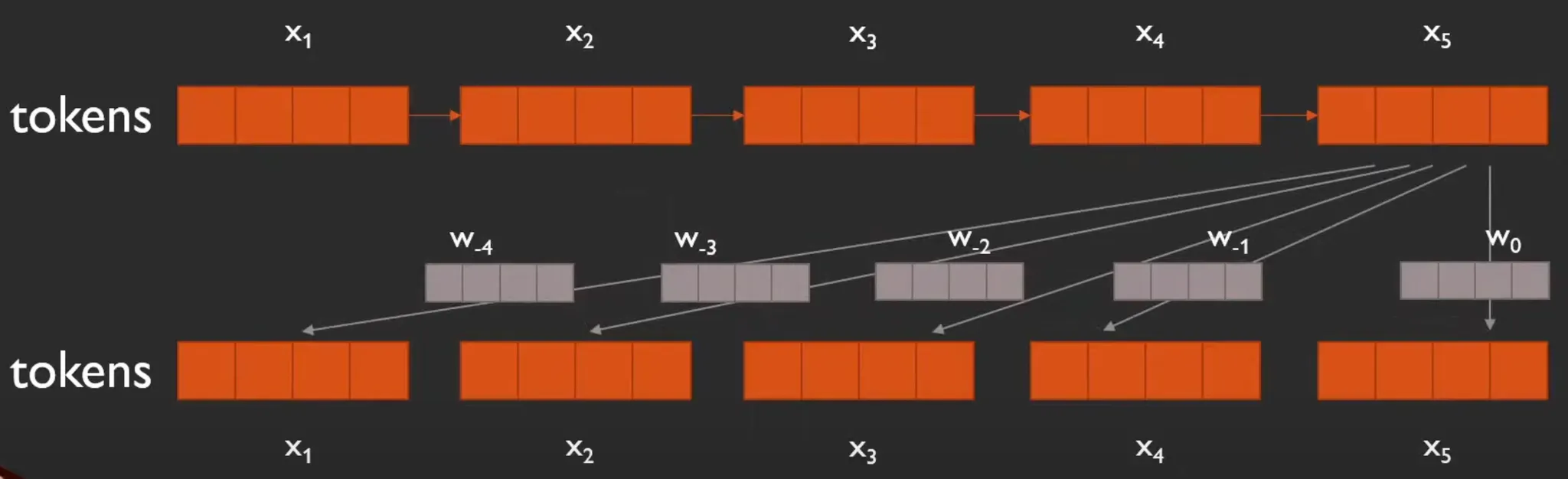
아래 사진과 같이, token과 token 사이의 관계를 모델링 할 때, learnable parameter ~를 사용하여 상대적인 위치를 encoding 할 수 있다.
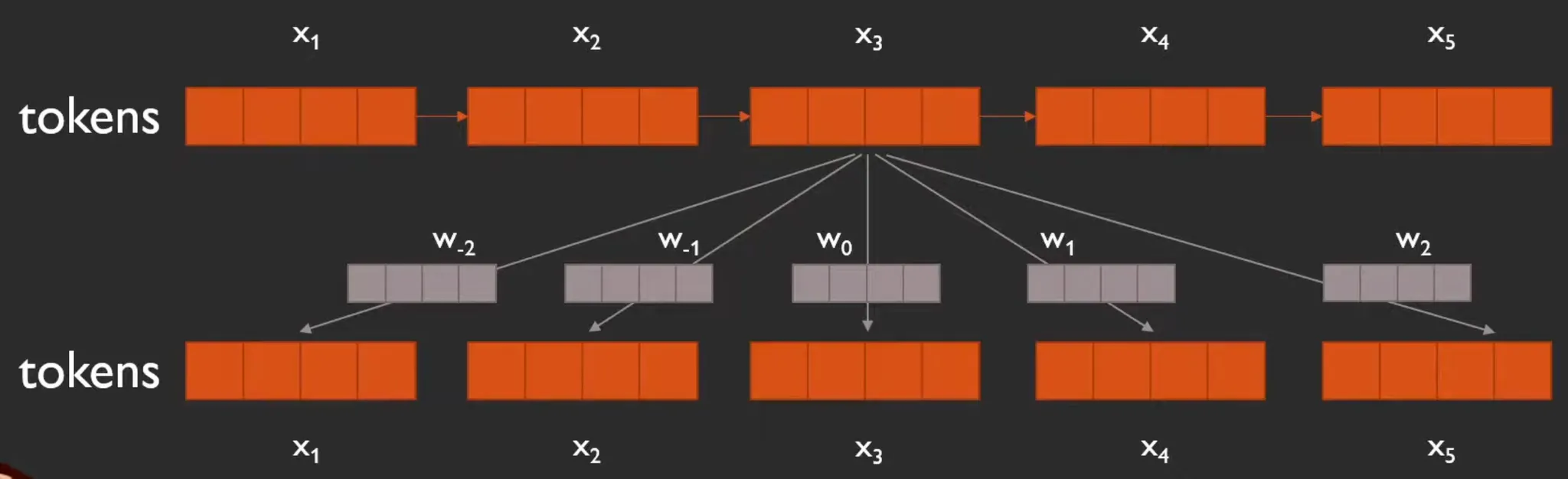
Detail
좀 더 구체적으로는, self-attention 수행 중 value와 key에 해당하는 부분에 learnable parameter 형태로 사용한다.
와 간의 interaction을 modeling하는 를 계산할 때, 아래 빨간 글씨로 표시된 가 추가된다.
또, output element 를 계산할 때, 가 추가된다.
참고로, 는 attention weight이다.
논문에서는 maximum relative position을 로 제한하여, 그 이상 떨어진 node와의 interaction은 모두 동일하게 간주하는 것도 제안하였다. 이를 통해서 training 시에 보지 못한 길이만큼 떨어져있는 것에 대해서도 infer할 수 있는 general한 능력도 생긴다고 한다.
Remark
•
단백질 구조 관련 모델들에서도 PE도 relative PE를 사용하기는 하지만, 조금 다른 방식으로 사용한다.
◦
아래는 AlphaFold2의 PE pseudo code이다.
