.png&blockId=797f8e0e-0d71-4ffb-bb1a-b54b3055146c&width=3600)

ICML, ‘17
Summary
•
MAML is a general and model-agnostic algorithm that can be directly applied to a model trained with gradient descent procedure.
•
MAML does not expand the number of learned parameters.
•
MAML does not place constraints on the model architecture.
Key words
•
Model agnostic
•
Fast adaptation
•
Optimization based approach
•
Learning good model parameters
Prelimiaries
Common Approaches of Meta-Learning and MAML
A few terminologies of meta-learning problems
1. Introduction
Goal of ideal artificial agent:
Learning and adapting quickly from only a few examples.
To do so, an agent must..
•
Integrate its prior experience with a small amount of new information.
•
Avoid overfitting to the new data.
→ Meta-learning has same goals.
MAML:
"The key idea of MAML is to train the model's initial parameters such that the model has maximal performance on a new task after the parameters have been updated through one or more gradient steps computed with a small amount of data from that new task."
Learning process of MAML:
MAML maximizes the sensitivity of the loss functions of new tasks.
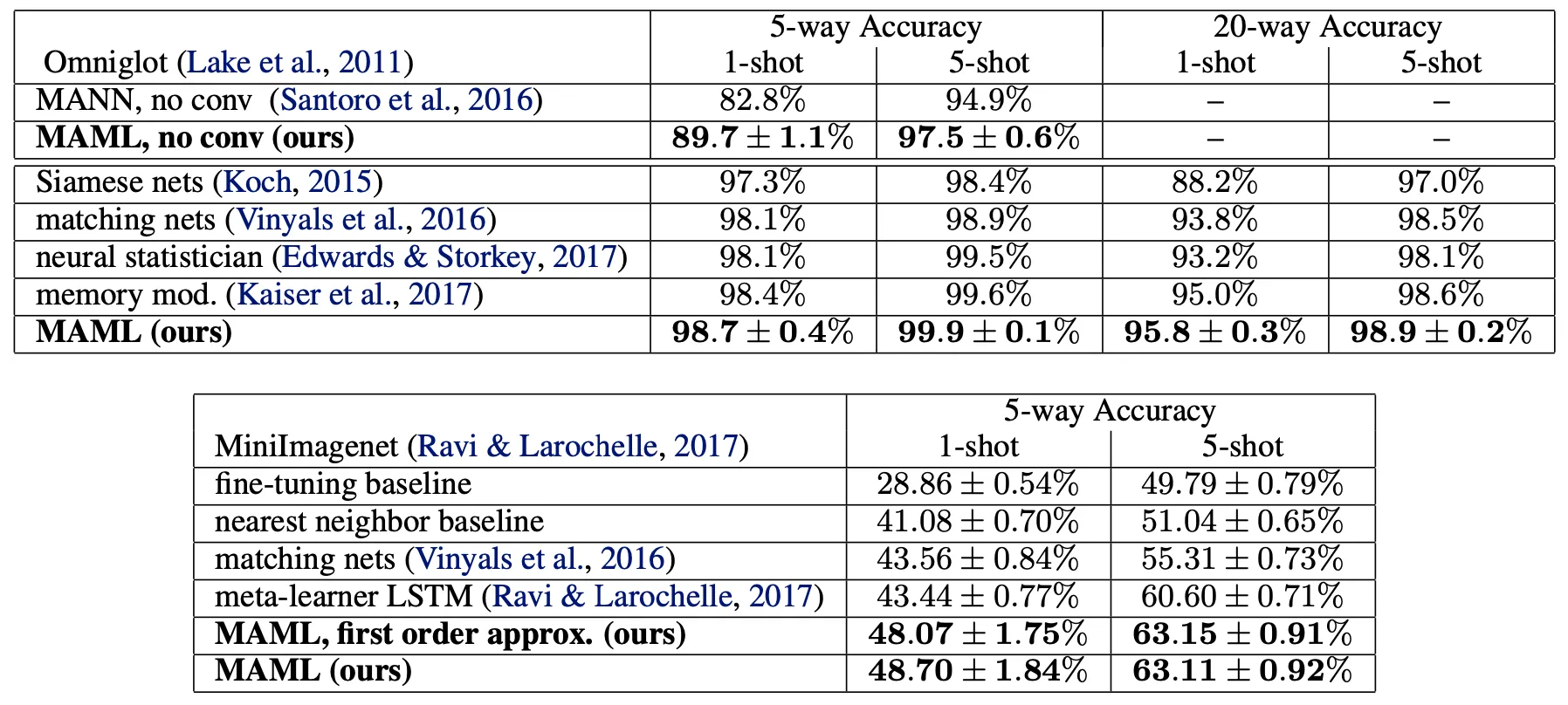
Authors demonstrated the algorithm on three different model types.
•
Few-shot regression
•
Image classification
•
Reinforcement learning
2. Model-Agnostic Meta Learning
2.1. Meta-Learning Problem Set-Up
To apply MAML to a variety of learning problems, authors introduce a generic notion of a learning task:
Each task consists of..
: a loss function, might be misclassification loss or a cost function in a Markov decision process
: a distribution over initial observations
: a transition distribution
: an episode length(e.g. in i.i.d. supervised learning problems, the length .)
Authors consider a distribution over tasks
Meta-training:
A new task is sampled from .
The model is trained with only samples drawn from .
Loss is calculated and feedbacked to model.
Model is tested on new samples from .
The model is then improved by considering how the error on new data from changes with respect to the parameters.
2.2. A Model-Agnostic Meta-Learning Algorithm
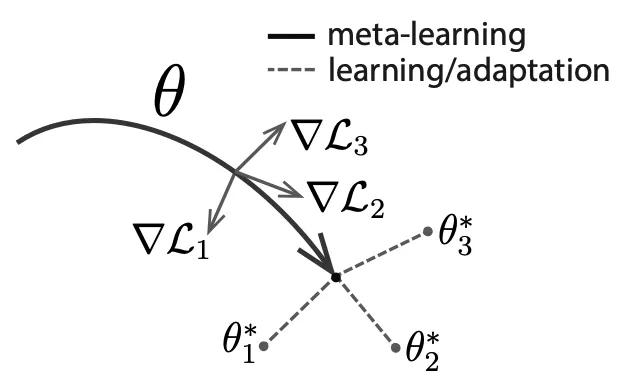
Intuition: Some internal representations are more transferrable than others. How can we encourage the emergence of such general-purpose representations?
•
A model has paramters .
•
For each task , 's parameters become .
•
Algorithm

cf) Terminologies for below description(temporarily defined by JH Gu)
◦
Divide tasks
1.
Separate tasks into meta-training task set() and meta-test task set().
(We can think of as monthly tests(모의고사), and as annual tests(수능))
2.
For each task, divide each samples into (task-specific samples for studying, also called as support set), (task-specific samples for checking, also called as query set)
(We can think of as 필수예제 in 수학의 정석, and as 연습문제 in 수학의 정석)
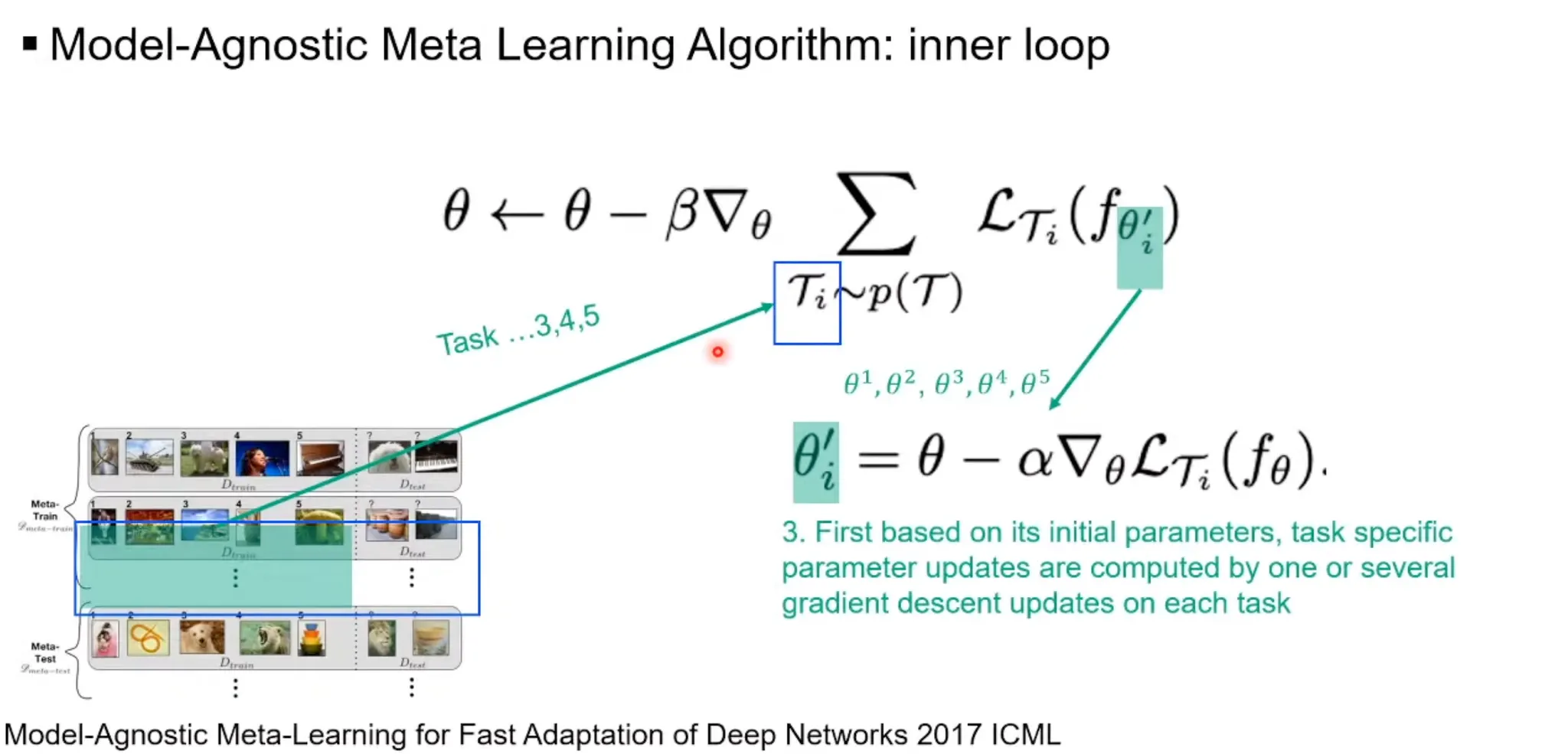
◦
Meta-training using meta-training task set
▪
Inner loop(task-specific -shot learning)
For each in , a new parameter is created.
1.
Each is initialized as .
2.
With task-specific samples for studying(), each is updated by:
▪
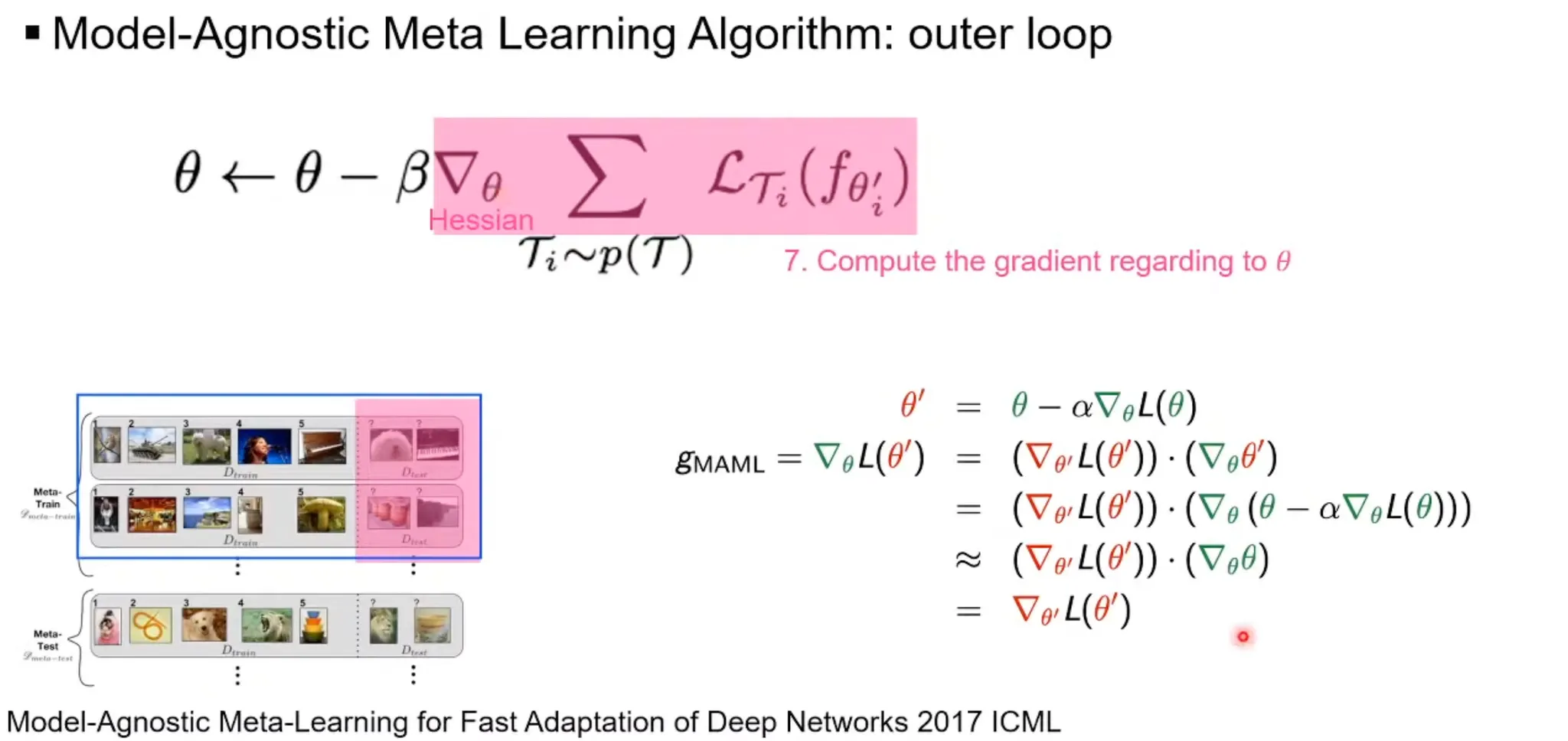
Outer loop(meta-learning across tasks)
1.
With task-specific samples for checking(), is updated by:
cf) second-order derivative(Hessian) problem
◦
Measure model performance using meta-test task set
1.
For each in , adjust task-specific parameters with .
2.
Test the performance with .
3. Species of MAML
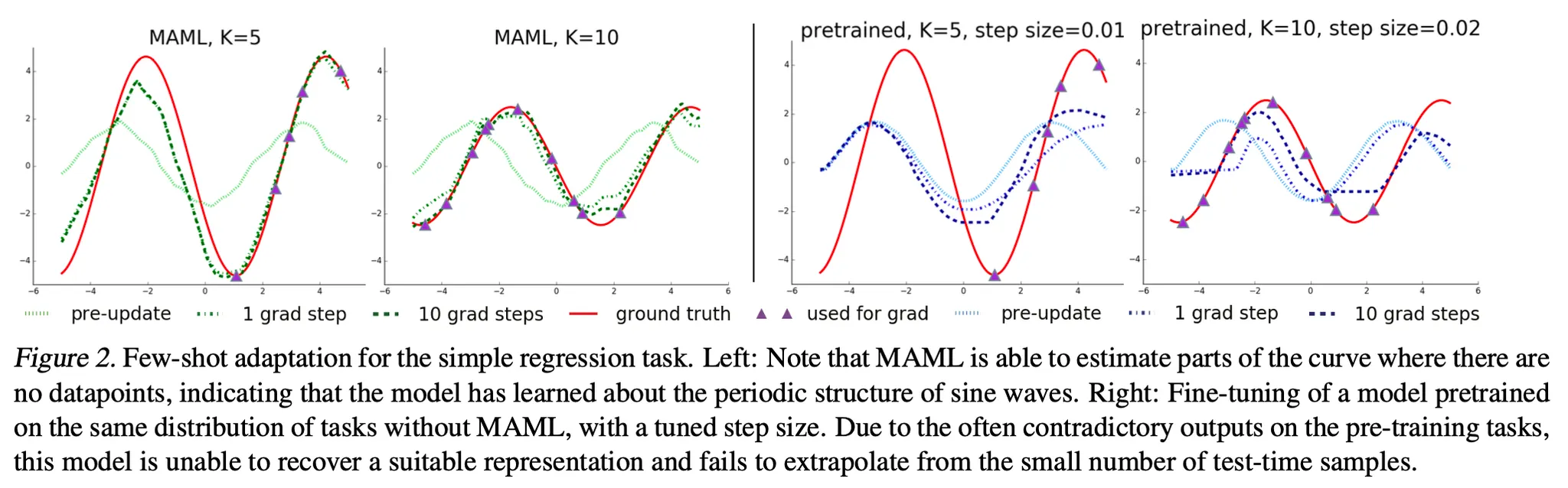
3.1. Supervised Regression and Classification
•
Algorithm

•
Formalizing supervised regression and classification
◦
Horizon
◦
Drop the timestep subscript on (since model accepts a single input and produces a single output)
◦
The task generates i.i.d. observations from
◦
Task loss is represented by the error between the model's output for and the corresponding target values .
•
Loss functions
◦
MSE for regression
◦
Cross entropy loss for discrete classification
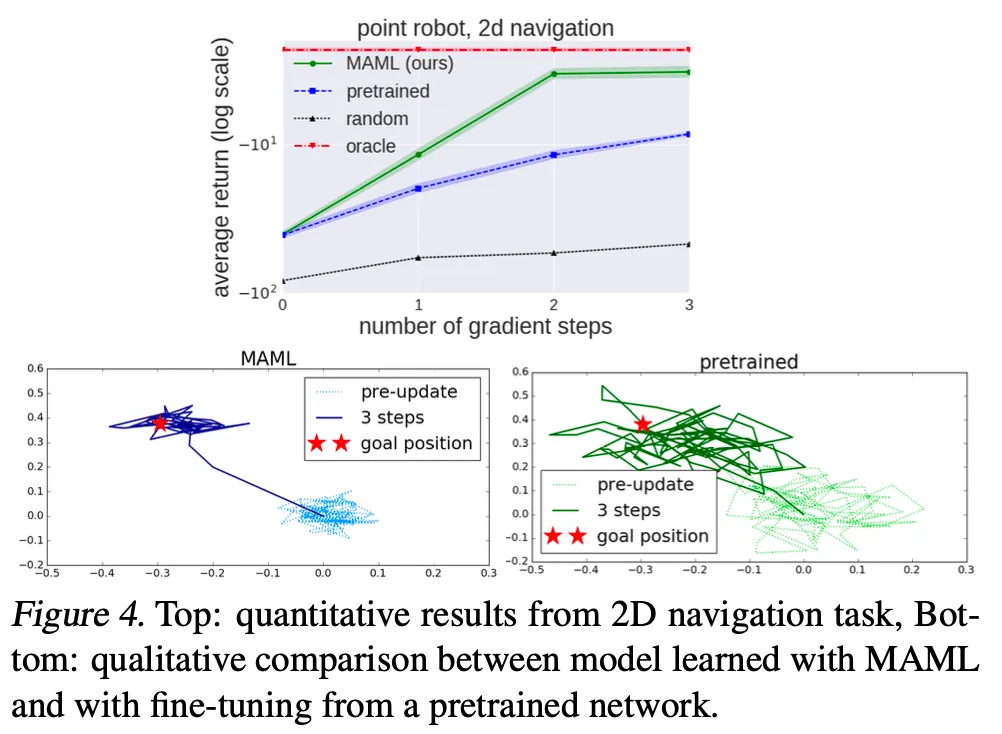
3.2. Reinforcement Learning
•
Algorithm

•
Goal of MAML in RL:
Quickly acquire a policy for a new test task using only a small amount of experience in the test setting.
•
Formalizing RL
Each RL task contains..
◦
Initial state distribution
◦
Transition distribution
▪
: action
◦
Loss , which corresponds to the negative reward function
Therefore, entire task is a Markov decision process(MDP) with horizon
The model being learned, , is a policy that maps from states to a distribution over actions at each timestep
•
Loss function for task and model :
•
Policy gradient method
Since the expected reward is generally not differentiable due to unknown dynamics, authors used policy gradient methods to estimate the gradient.
The policy gradient method is an on-policy algorithm
→ There are additional sampling procedures in step 5 and 8.
4. Comparison with related works
Comparison with other popular approaches
•
Training a meta-learner that learns how to update the parameters of the learner's model
ex) On the optimization of a synaptic learning rule(Bengio et al. 1992)
→ Requires additional parameters, while MAML does not.
•
Training to compare new examples in a learned metric space
ex) Siamese networks(Koch, 2015), recurrence with attention mechanisms(Vinyals et al. 2016)
→ Difficult to directly extend to our problems, such as reinforcement learning.
•
Training memory-augmented models
ex) Meta-learning with memory-augmented neural networks(Santoro et al. 2016)
The recurrent learner is trained to adapt to new tasks as it is rolled out.
→ Not really straightforward.
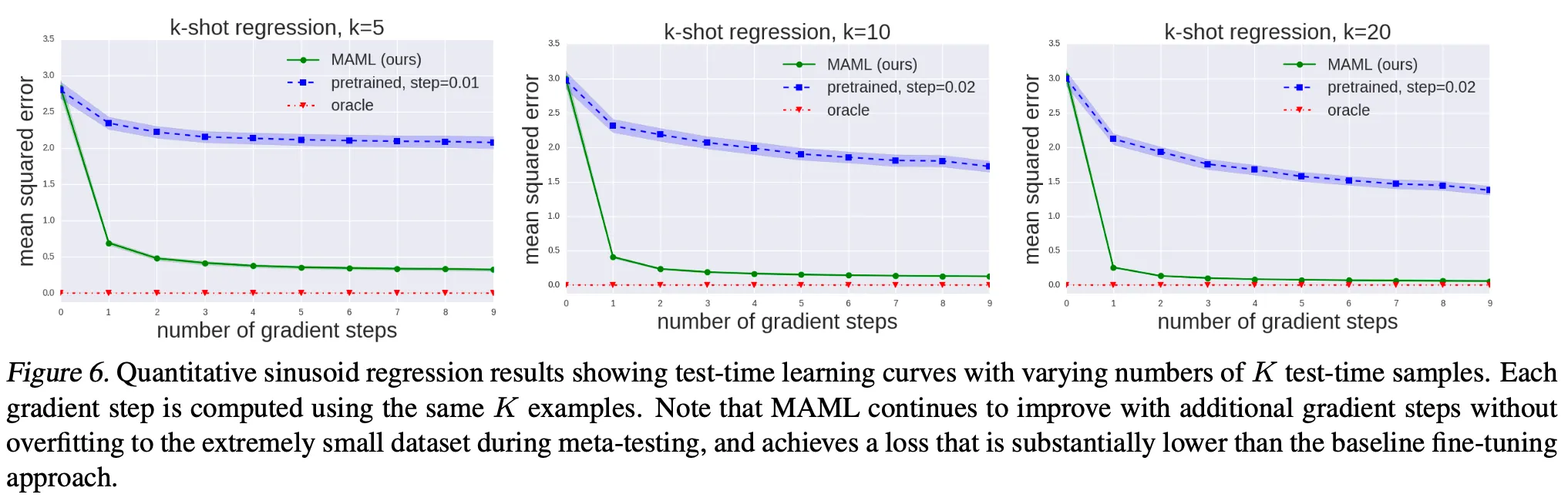
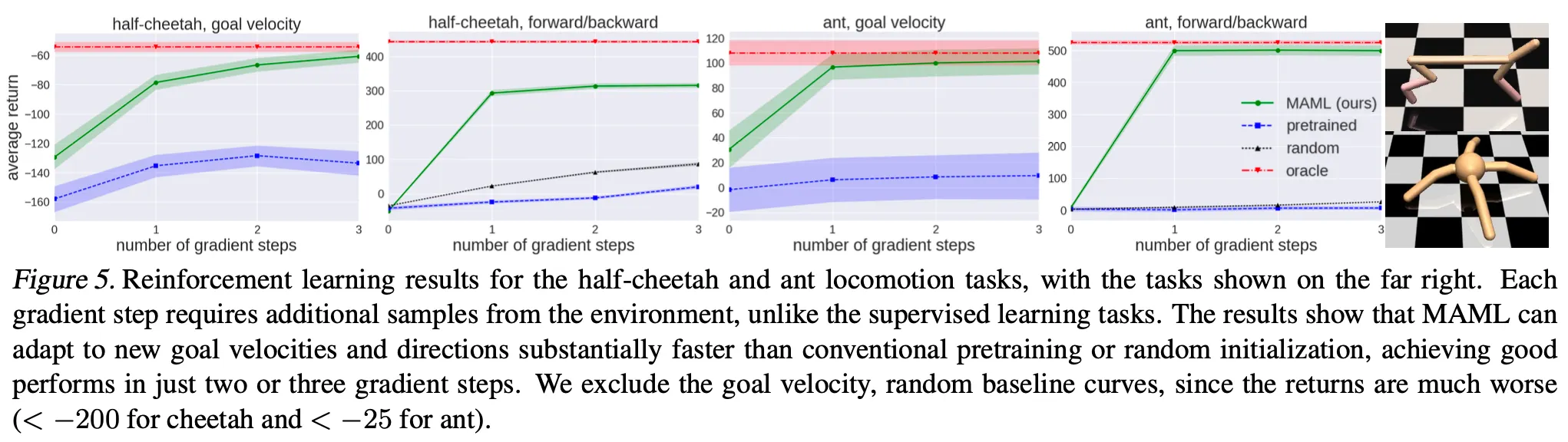
5. Experimental Evaluation
Three questions
1.
Can MAML enable fast learning of new tasks?
2.
Can MAML be used for meta-learning in multiple different domains?
3.
Can a model learned with MAML continue to improve with additional gradient updates and/or examples?