

Index
Abstract
Graph Attention Networks (GATs) are one of the most popular GNN architectures and are considered as the state-of-the-art architecture for representation learning with graphs.
In GAT, every node attends to its neighbors given its own representation as the query.
However, in this paper we show that GAT computes a very limited kind of attention: the ranking of the attention scores is unconditioned on the query node.
We formally define this restricted kind of attention as static attention and distinguish it from a strictly more expressive dynamic attention.
Because GATs use a static attention mechanism, there are simple graph problems that GAT cannot express: in a controlled problem, we show that static attention hinders GAT from even fitting the training data.
To remove this limitation, we introduce a simple fix by modifying the order of operations and propose GATv2:a dynamic graph attention variant that is strictly more expressive than GAT.
We perform an extensive evaluation and show that GATv2 outperforms GAT across 12
OGB and other benchmarks while we match their parametric costs.
세 줄 요약
1. 다들 GAT로 이거(Veličković et al.) 쓰던데,
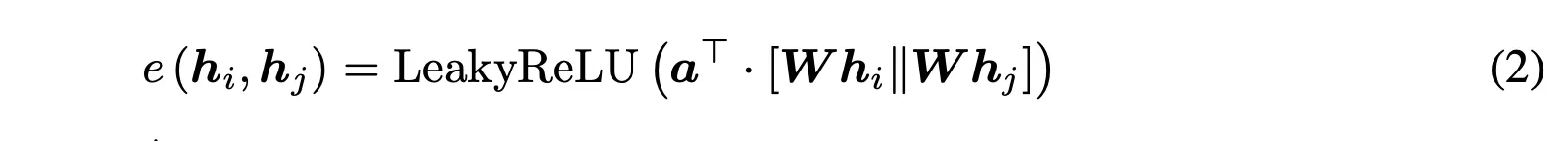
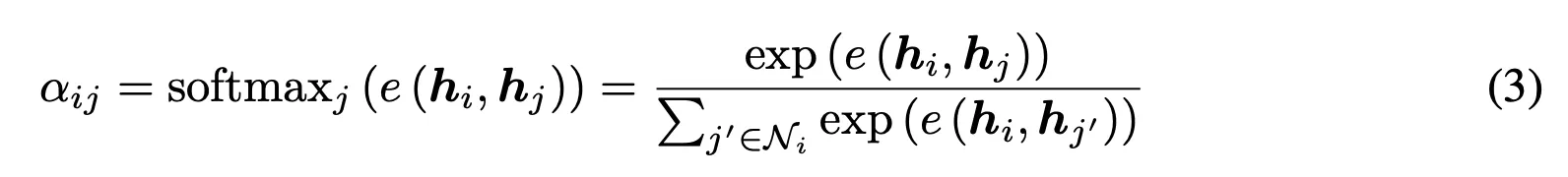
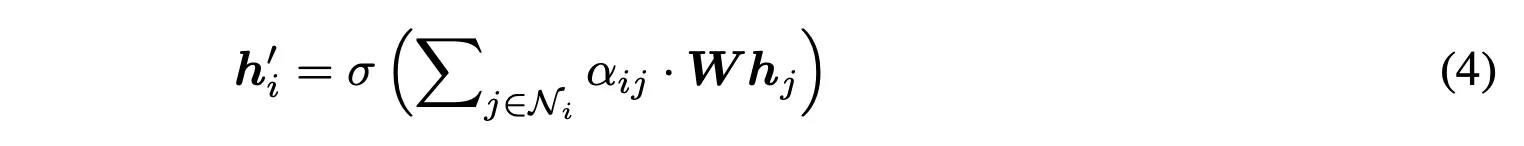
2. 그거 쓰면 Attention이 static하더라
증명
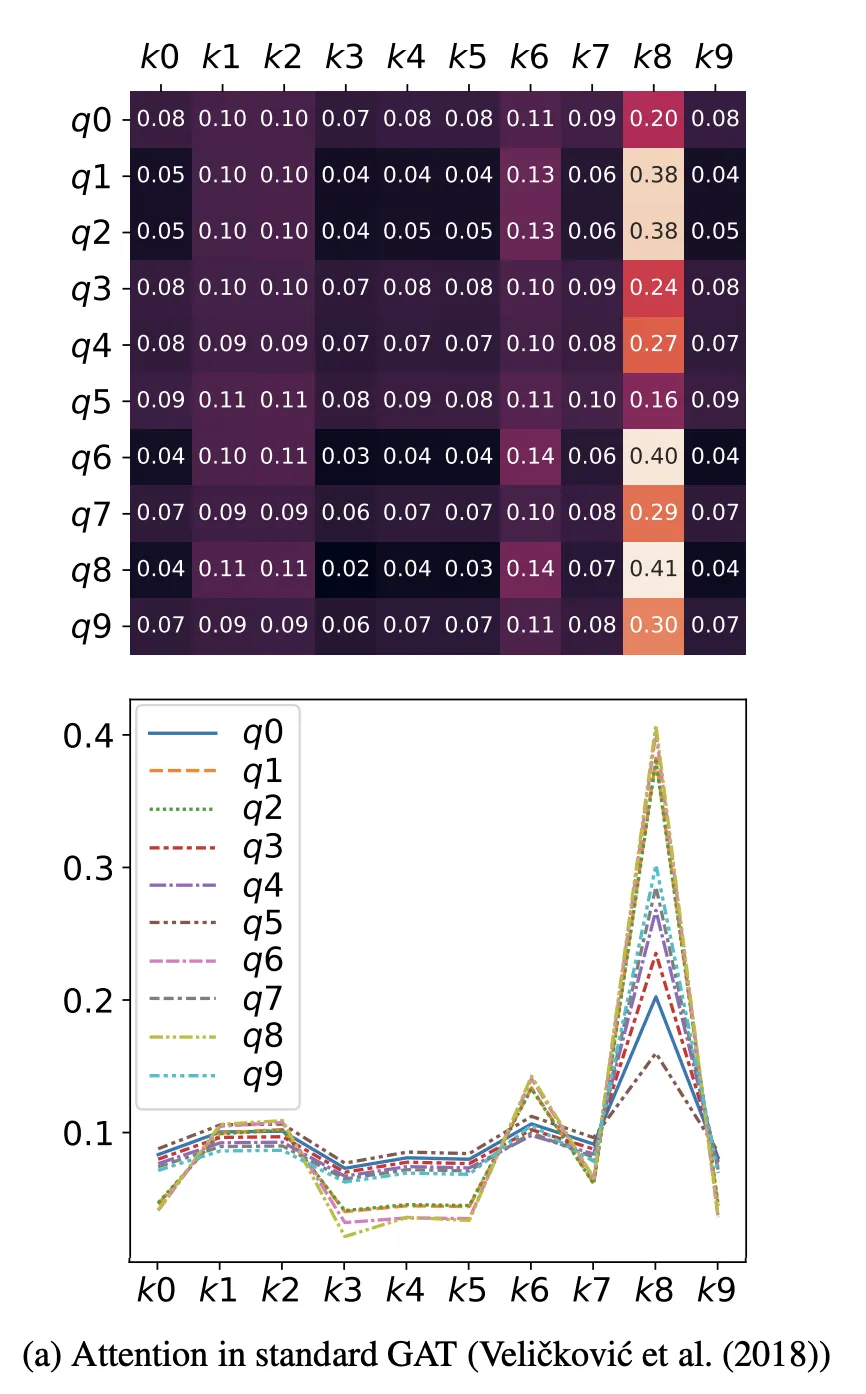
query에 관계 없이 동일한 key(k8)에 가장 점수가 높음. 점수들의 순서도 k8 > k6 > ~~ 으로 모두 동일.
•
static attention := 모든 query에 대해 최고 attention score을 받는 key가 동일함
•
심지어 (Veličković et al.)거 쓰면 query에 상관없이 key들의 attention score ranking까지 동일함
•
경험적으로만 그런 게 아니라, 항상 그렇다는 증명도 할 수 있음.
•
attention은 query에 맞게 key를 잘 골라야 하는 모듈인데, query에 상관 없이 똑같은 key에만 집중하는 attention이면 써 먹겠음?
3. 그래서 우리가 연산 순서만 바꿔 봤더니(GATv2) 이제 static 하지 않음
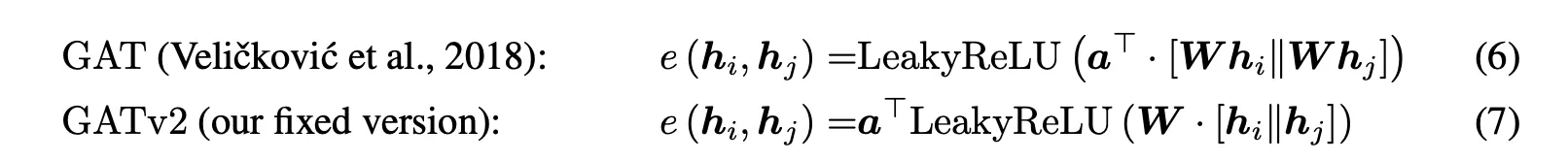
query에 따라 서로 다른 key에 집중하게 됨
•
12개 벤치마크로 성능 테스트해봤더니 GAT보다 GATv2가 더 잘함.
실험 결과들
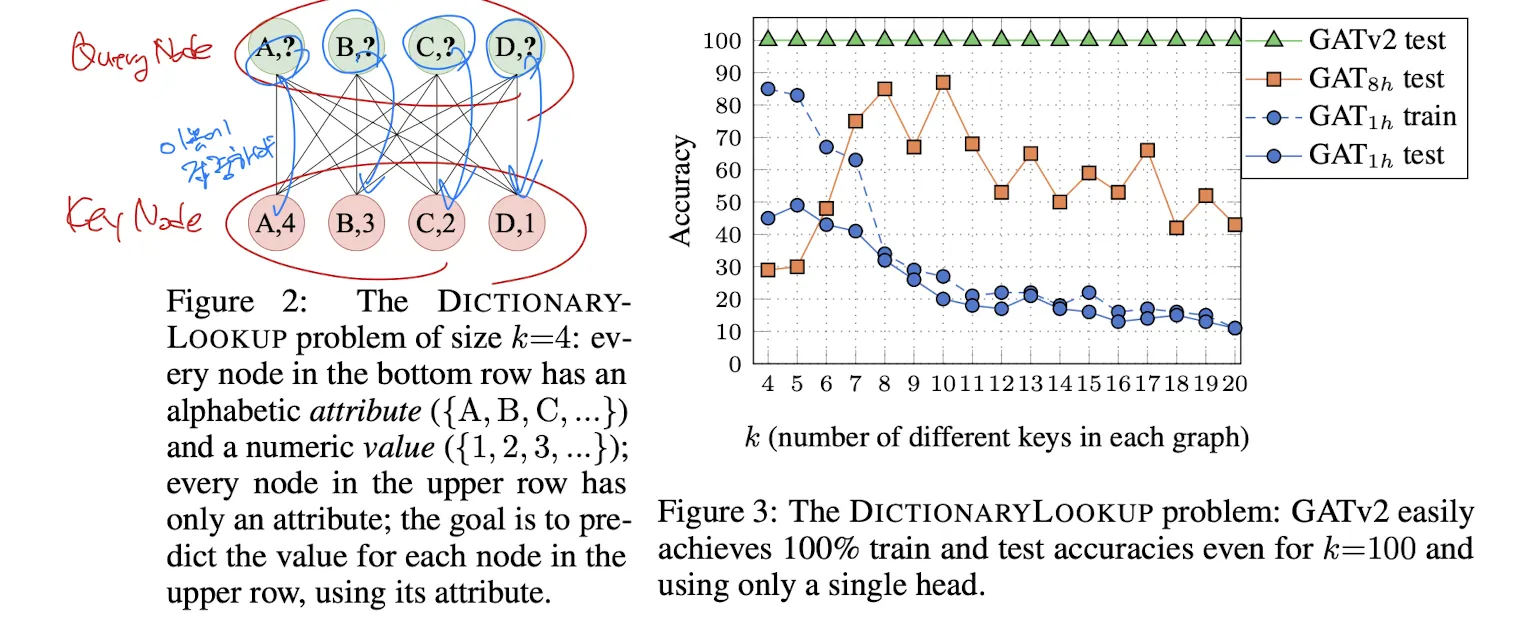
1. DictionaryLookup
•
Dynamic Attention이 되는지를 확인할 수 있는 합성 데이터셋
•
Query Node(attribute만 있음)와 Key Node(attribute, value가 모두 있음)가 주어졌을 때, Query Node에 대해 value를 예측하는 문제
•
query node에 대해 동일한 attribute를 갖는 key node에 집중하여 문제를 해결할 수 있음
•
성능?
◦
GATv2는 v1 하이퍼파라미터 그대로 쓰고, 파라미터 숫자도 동일하게 맞춰줬는데도 성능이 월등하다.
◦
애초에 GATv1는 head가 하나일 때는 학습도 되지 않았고, head가 늘어나는 족족 검증 성능이 올라간다(표현력이 제한적이다).
◦
GATv2는 헤드가 하나여도 성능이 좋다: 일반화 성능이 이미 뛰어나다.
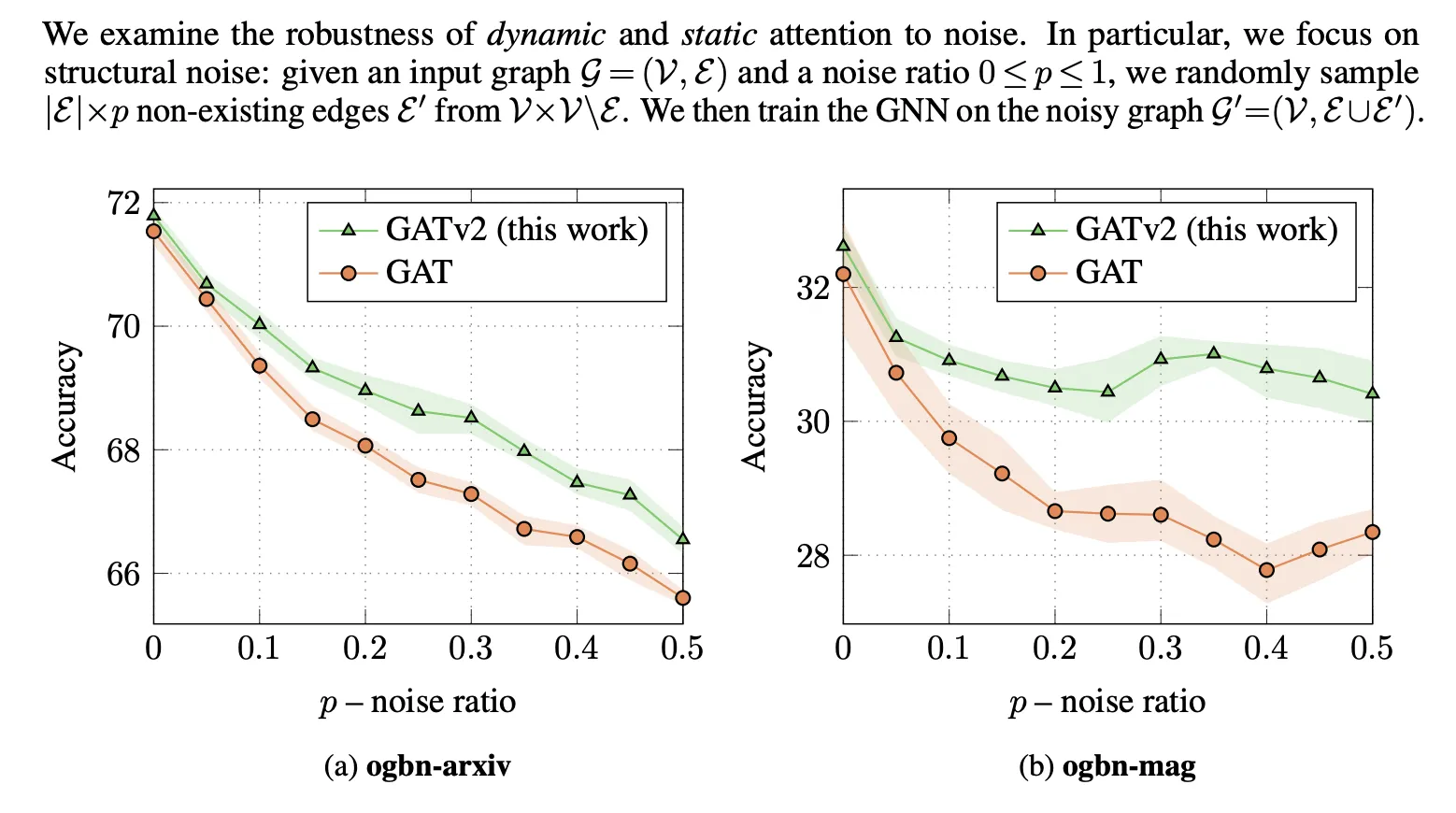
2. Robustness to Noise
•
두 개의 Node Prediction 문제(ogbn-arxiv|mag)에서, 실제 그래프에 없는 엣지를 p의 비율로 임의로 추가하여(노이즈) Task 성능을 확인
•
역시 GATv2가 더 성능 좋다.
•
dynamic attention이 노이즈와 노이즈가 아닌 엣지를 구분할 수 있게 되기 때문일 것이다.
3. VarMisuse: Node-Pointing Problem
VarMisuse
•
입력에 대한 최적 노드를 선택하는 문제
•
노드 간 상호작용 종류가 복잡다양(11종의 상호작용)
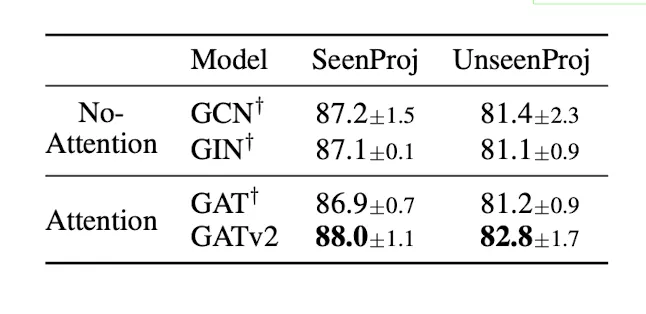
•
역시 v2>v1
4. Node-Prediction
•
노드의 속성을 예측하는 문제
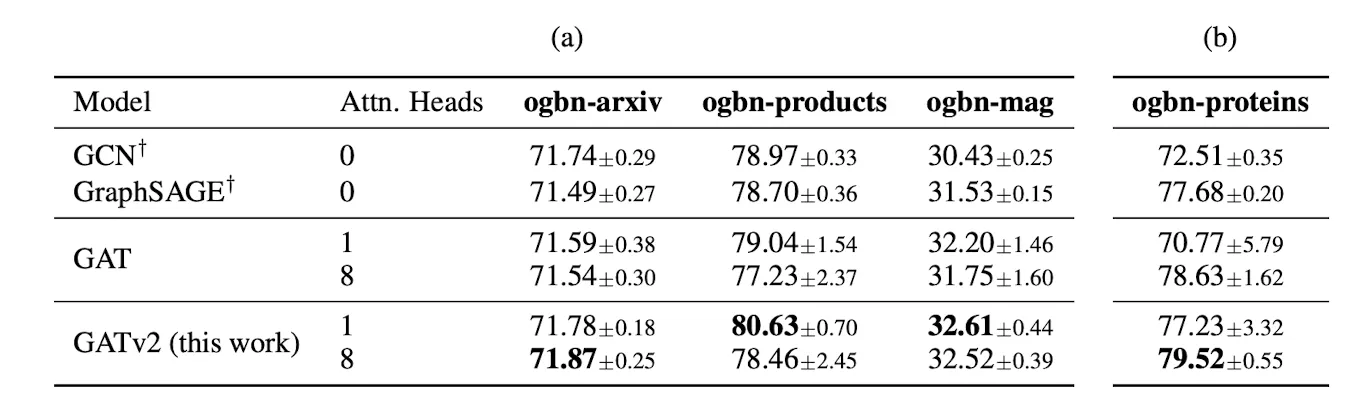
•
v2 > v1
•
proteins 문제에서 v1는 헤드 수를 늘려야 잘하지만, v2는 헤드 하나도 충분히 잘한다
5. Graph-Prediction
•
그래프 자체의 속성을 예측하는 문제
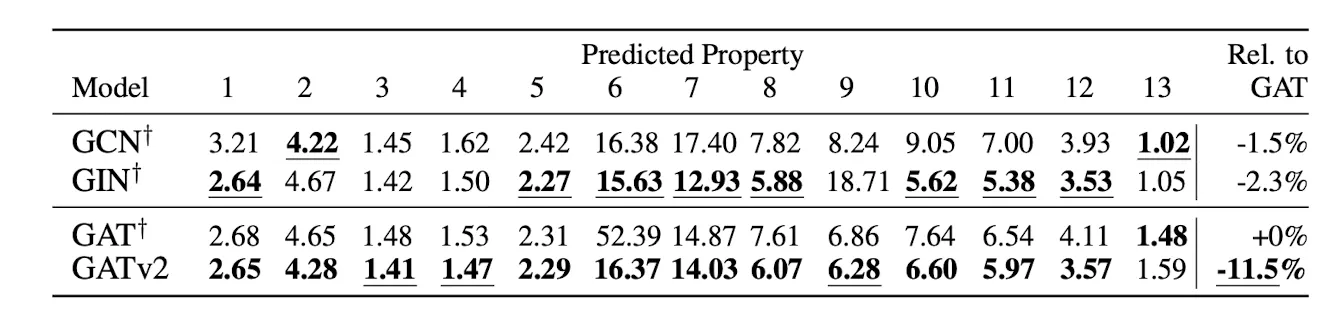
•
v2 > v1
•
근데 몇몇 속성에 대해서는 Attention이 없는 친구들이 더 잘한다.
6. Link-Prediction
•
노드 간 연결 관계를 예측하는 문제
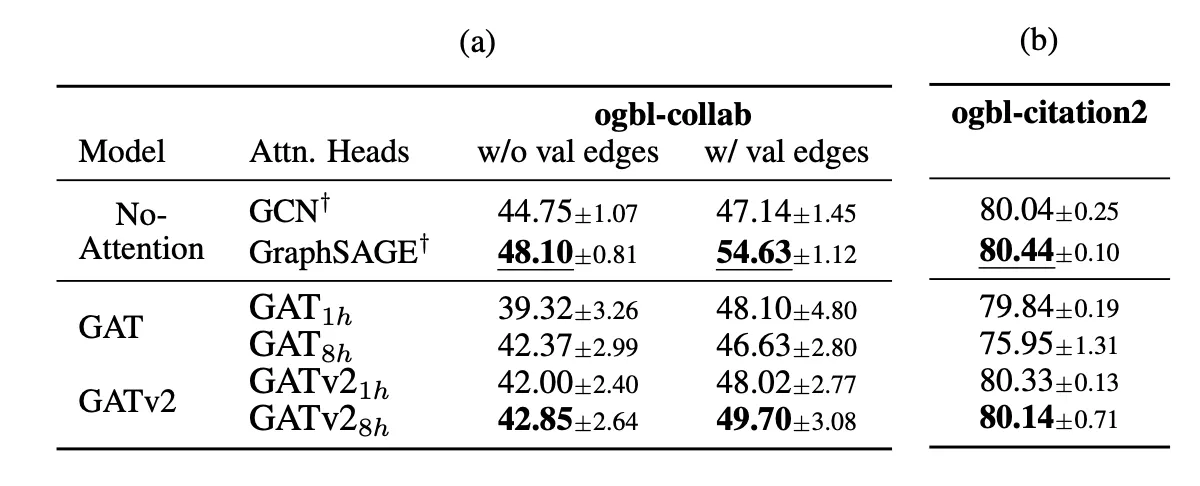
•
v2 > v1
•
근데 Attention이 없는 친구들이 훨씬 더 잘한다. 왜?
◦
가설: 평균적으로 high-degree인 그래프에서 attention이 더 적합할 것
◦
ogbn-proteins(avg deg=597), ogbn-products(avg deg=50.5)에서는 attention 있는 모듈들이 더 잘했음
◦
dynamic attention 성질은 degree가 높고 relevant 노드를 잘 선택해야 하는 경우에 유용할 것
결론

static attention밖에 안 되는 문제의 실제 데이터셋에서의 한계를 지목한 건 우리가 처음이다.

Velickovic도 GATv1은 global node importance가 적용되는 상황에서 좋다고 얘기했다.

그래서 연산 순서만 바꿔서 v2 만들었다. 연산 복잡도 동일한데 dynamic attention 되고 성능은 더 뛰어나다.